It's a Small World After All
In this article, we will look at this phenomenon from a mathematical perspective and learn how human networks are organized, perhaps unwittingly, to create this phenomenon. ...
Introduction
Many of us are surprised, at one time or another, to meet a person by chance and later discover that we have some kind of connection or a friend in common. We scratch our heads and say, "Gee, it's a small world."
This experience was investigated in the 1960s by the social psychologist Stanley Milgram through a classic experiment. A group of participants living in Omaha, Nebraska was randomly chosen, each of whom was asked to send a folder by mail to a target participant in Sharon, Massachusetts, just outside Boston, subject to this rule:
If you do not know the target person on a personal basis, do not try to contact him directly. Instead, mail this folder ... to a personal acquaintance who is more likely than you to know the target person ... it must be someone you know on a first-name basis.
Beginning with 160 participants in Nebraska, 44 of the folders, or 27.5%, were successfully delivered to their target through a chain of intermediaries. Somewhat surprisingly, the completed chains required a relatively small number of intermediaries; the median number of intermediaries was five, with one chain being completed with only two intermediaries. This experiment has entered our cultural imagination through the phrase "six degrees of separation," as the completed chains required a median of six legs on their journey.
This experiment has been repeated in other forms. Most recently, a study of the structure of friendships on Facebook, which included 721 million individuals and 69 billion friendship links, found that two Facebook users are separated by an average distance of 4.74 links or 3.74 intermediaries. Of course, one could argue the degree to which Facebook friendship mirrors real-life acquaintanceship, but this is still a remarkable result considering Facebook's international audience.
Once you start looking, you will see this phenomenon all around. For instance, the trivia game Six Degrees of Kevin Bacon links actors together when they have appeared together in a movie. As of last year, no actor was more than eight links away from Kevin Bacon.
The Oracle of Baseball links baseball players if they have ever played on the same team creating a chain between Babe Ruth and Justin Verlander with just five intermedaries.
Mathematicians have their own version in which mathematicians are linked if they have published a mathematics paper together. Mathematicians sometimes cite their Erdős number, which is the length of the smallest chain connecting them to the prolific mathematician Paul Erdős.
In Milgram's original experiment, individuals, aware of only their own acquaintances, lacked any deeper knowledge of the global structure of the network. So while it is surprising that individuals are connected by relatively short chains, it is even more suprising that the participants were able to find these chains.
A network in which most pairs of individuals are linked by short chains though they may be separated by large geographic distances is known as a small-world network. In addition, when individuals may find these short chains using only local information, we say the network is searchable.
In this article, we will look at this phenomenon from a mathematical perspective and learn how human networks are organized, perhaps unwittingly, to create this phenomenon.
The Watts-Strogatz model
Before beginning, let's think about what features we would like to build in to our mathematical model. First, the majority of our acquaintances are with people who are geographically close to us through, say, family, co-workers, and friends at school. Second, many of our acquaintances are also acquainted with each other. For instance, two of our co-workers are likely to be acquainted as well. Finally, most of us have a smaller number of acquaintances who are further removed geographically, such as friends or family members who have moved away. In spite of the fact that the Internet now facilitates more far-flung friendships, a considerable amount of current research supports these assumptions.
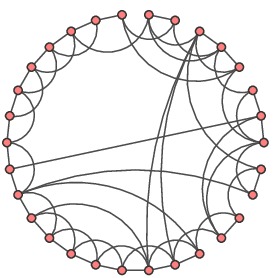
The first model we'll consider was introduced by Watts and Strogatz in the late 1990s in an attempt to understand whether our three assumptions are enough to create small-world networks. The model begins with $n$ nodes arranged in a ring, with each node linked to its $k$ closest neighbors. Here is an example with $n=30$ nodes and $k=4$ links to neighbors:

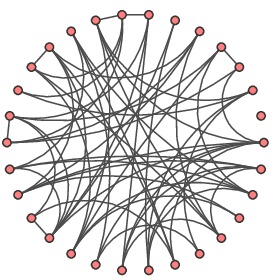
To include some long-range links in our model, we will consider each edge and, with probability $p$, change one of the endpoints to another randomly chosen node. In this way, we create a a family of networks by varying the parameter $p$ in the range $0\leq p\leq 1$.
|
|
 |
|
$p=0$ |
$p=0.01$ |
 |
 |
|
$p=0.1$ |
$p=1$ |
At the end of the spectrum where $p=0$, none of the edges are rewired, and we have a completely regular network. On the other end where $p=1$, every edge is rewired, and we have a completely random network. In this way, the parameter $p$ interpolates between completely regular and completely random behavior.
Watts and Strogatz characterize these networks with two quantities. The first, denoted $L(p)$, measures the average distance between nodes in the network, while the second, denoted $C(p)$, measures the amount of clustering in the network. More specifically, $L(p)$ is the number of links in the shortest path between a pair of nodes, averaged over all pairs of nodes. In a small-world network, we would expect that most pairs are joined by relatively short chains of links and that $L(p)$ is therefore relatively small.
Remember that each node is connected to its $k$ nearest neighbors when $p=0$. Among these $k$ neighbors, there are possibly $k(k-1)/2$ links. Given a node in our network, we may ask what fraction of these links actually exist. The clustering coefficient $C(p)$ is the average of this fraction over each of the nodes. In practical terms, this quantity measures the number of our acquaintances who are also acquaintances. We are therefore interested in networks with a high clustering coefficient.
Following Watts and Strogatz, I performed an experiment in which I looked at networks with $n=1000$ nodes and $k=10$ nearest neighbors. For many values of $p$, I created twenty networks for which I computed $L(p)$ and $C(p)$. The plot below shows the averages, normalized by their values at $p=0$, on a logarithmic scale.

The important point to notice is that there is a very large range of probabilities $p$, roughly $0.001< p < 0.1$, in which $L(p)$, the average distance between nodes, is relatively small, and the clustering coefficient $C(p)$ is relatively large. These are the conditions that we desire for a small-world network so we conclude that it is relatively easy to create small-world networks. In other words, it doesn't take a lot of long-range links to create a small world.
Speaking quantitatively, $L(0)$ is proportional to $n$. For values of $p$ values that give a small world, however, $L(p)$ is less than a polynomial in $\log(n)$.
Watts and Strogatz applied this kind of analysis to the network of film actors described above, the power grid in the western United States, and neural network of the nematod worm C. elegans. All three examples demonstrate the properties of a small world. From this, they speculate that the small-world property is probably ubiquitous in the real world.
Comments?
How can we find short chains of links?
While it is surprising that short chains of links existed in Milgram's experiment, it is perhaps even more surprising that they could be found by the participants, given the limited information they possess. For instance, if we knew the structure of the entire network---that is, if we knew everyone's acquaintances---it would be relatively straightforward to find the shortest chain. However, individual participants are aware of only their own acquaintances. With this information, how are short chains discovered?
A hint is given by this figure of Milgram's, in which the geographic locations of each of the intermediaries in one of the successful chains is given.

Notice how each intermediary sent the folder to a person who is geographically closer to the target; remarkably, the distance is roughly halved at each step.
This led Kleinberg to study a new model for networks that is based on the Watts-Strogatz model and that incorporates geographic distance in the distribution of links. Kleinberg's model begins with nodes on a uniform two-dimensional $n\times n$ lattice (we may use a lattice in any dimension $k$).
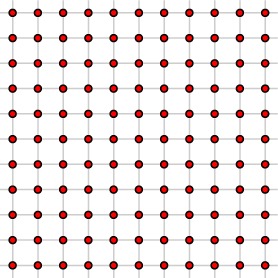
There is a natural notion of geographic distance between any two nodes; we define $d(u,v)$, the distance between nodes $u$ and $v$, to be the smallest number of steps needed to walk from one node to the other along the grid.
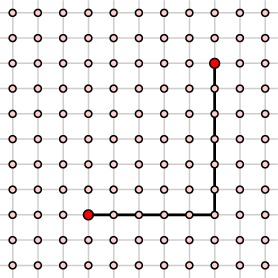
Generalizing the network of Watts and Strogatz, Kleinberg assumed that any node had links to all nodes within a chosen distance $p$ and then added $q$ long-range links chosen at random. For instance, when $p=2$ and $q=3$, the red node in the center may be linked to the blue nodes.

So far, this is nothing more than a two-dimensional version of the Watts-Strogatz model. The novel feature about Kleinberg's model is that the long-range links are chosen to favor shorter ones over longer ones. For instance, I live in Michigan; in Kleinberg's model, it is more likely that I have a long-range connection to someone in Illinois than to someone in France.
In particular, we will introduce a parameter $\alpha\geq0$ and choose a long-range connection linking $u$ to $v$ with probability proportional to $d(u,v)^{-\alpha}$: $$ {\rm Pr}[u\to v]\propto \frac{1}{d(u,v)^\alpha}. $$
When $\alpha=0$, we have the Watts-Strogatz model in which long-range links are chosen without reference to the geographic distance between nodes. However, when $\alpha=1$, the probability that a long-range links exists between $u$ and $v$ is inversely proportional to the distance between the nodes.
Kleinberg then proposed an algorithm that models the dynamics of the Milgram experiment: at each step, the intermediary sends the folder to his acquaintance that is closest to the target. In this way, each intermediary uses only his knowledge of his own acquaintances and not the entire structure of links in the network.
We imagine that the folder requires one unit of time to move from one acquaintance to another and determine the delivery time $T$ required for the folder to move from the source to the target.
I repeated a simulation of Kleinberg's by studying a lattice of 20,000 by 20,000 nodes placed on a torus to minimize boundary effects. With fixed values of $\alpha$, $p$, and $q$, I constructed 1000 networks finding, for each, the delivery time given by the algorithm between two fixed nodes. To summarize the results, the logarithm of the delivery time $T$ is plotted below as a function of $\alpha$.

This simulation clearly shows that there is a optimum value of $\alpha$; that is, in networks constructed with $\alpha\approx2$, the average delivery time is shortest.
In fact, Kleinberg provides a theoretical understanding of this result through two results:
When $\alpha=2$, the average delivery time is at most proportional to $(\log(n))^2$.
For other values of $\alpha$, the average length of chains produced by the algorithm is at least proportional to $n^\beta$ where $\beta$ is described in the graph below.

Remember that a pair of nodes in a small-world network is, on average, joined by a chain whose length is bounded by a polynomial in $\log(n)$. The upshot of Kleinberg's study is that these short chains may be found by this algorithm--that is, the network is searchable--only when $\alpha=2$.
Kleinberg's analysis is guided by the diagram in Milgram's paper, which shows that at each step, the distance to the target is roughly halved. In the same way, we will consider, at each step of the folder's journey, the distance to the target in our small-world network, and ask how long it takes to halve that distance.
Easley and Kleinberg encourage us to think of this strategy through "scales of resolution." For instance, to deliver a letter to a distant person, we first find the country, then the state, the city, the street, and then the house. What we will see is that in the network constructed with $\alpha=2$, the folder spends roughly the same amount of time in each one of these scales.
We will say that the folder is in phase $j$ if the distance from the folder's current holder $u$ to the target $t$ is greater than $2^j$ and at most $2^{j+1}$. We therefore ask how long the folder spends in phase $j$ before entering phase $j-1$.
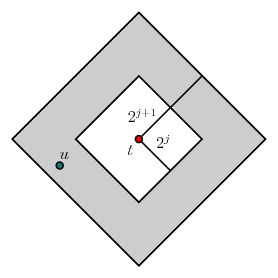
Since the geographic distance from the original source to the target is less than $2n$, the phase in which the folder starts out is no more than $\log(n)+1$. Consecutively, there are at most $\log(n)+1$ phases that the folder passes through. When $\alpha=2$, we will see that the time spent in each phase is roughly constant and proportional to $\log(n)$.
Let's think about this informally from the point of view of "scales of resolution" before digging into a more careful argument. Assuming the folder is at some node $u$, let's ask what the chances are that $u$ has a long-range link into the annular region shown below.

How many points are in this annular region? Since the number of nodes in each disk is proportional to $d^2$, the number of nodes in the annular region is also proportional to $d^2$. The probability that there is a long range link to a node in that region is between $1/(2d)^2$ and $1/d^2$. Multiplying the number of nodes in the annular region by the probability of choosing one of the nodes in the annular region gives an approximate result that is independent of $d$.
In this way, we see that the long-range links from $u$ are distributed uniformly over all scales when those links are randomly chosen with $\alpha=2$. We therefore expect that the time spent in each phase of the folder's journey to be independent of the phase.
Notice that this value of $\alpha$ is adapted to the underlying two-dimensional geometric structure of the network. If we instead choose another network based on a $k$-dimensional grid, we should expect that $\alpha=k$ will be the exponent that enables our algorithm to find short paths.
Let's make this precise. Suppose that we are currently in phase $j$ with the folder held by $u$. We would like to estimate how long it takes us to move into phase $j-1$ by passing the folder to a node $v$ whose distance to $t$ is no more than $2^j$.

First, we have said that long-range links are chosen with probability proportional to $d^{-2}$. Let's estimate the constant of proportionality. If we are at node $u$, then the probability of choosing a long-range link to node $v$ is
$${\rm Pr}[u\to v] = \frac{d(u,v)^{-2}}{\sum_{u\neq w}d(u,w)^{-2}}.$$
To estimate the denominator, we know that there are $4d$ nodes at distance $d$ from $u$ and that the distance between nodes is bounded by $2n-2$, a distance realized by nodes at opposite corners of the lattice. Therefore,
$$ \begin{eqnarray*} \sum_{u\neq w} d(u,w)^{-2} & \leq & \sum_{d=1}^{2n-2} 4d\cdot d^{-2} \\ & \leq & \sum_d^{2n-2} 4/d \\ & \leq & 4+4\ln(2n-2) \\ & \leq & 4\ln(6n). \end{eqnarray*} $$
This means that the probability of a long-range link existing between $u$ and $v$ is greater than
$${\rm Pr}[u\to v] \geq \frac{1}{4\ln(6n) d(u,v)^2}.$$
 We will now estimate the probability that a long-range link reduces the folder's current phase. In this case, the distance from $u$ to the target $t$ is at most $2^{j+1}$. To reduce the phase, we need to find a long-range link to a node $v$ within a distance of $2^j$ of $t$. This means that $$d(u,v)\leq 2^{j+1}+2^j < 2^{j+2}.$$
We will now estimate the probability that a long-range link reduces the folder's current phase. In this case, the distance from $u$ to the target $t$ is at most $2^{j+1}$. To reduce the phase, we need to find a long-range link to a node $v$ within a distance of $2^j$ of $t$. This means that $$d(u,v)\leq 2^{j+1}+2^j < 2^{j+2}.$$
For these nodes $v$, we then have $${\rm Pr}[u\to v] \geq \frac{1}{4\ln(6n) (2^{j+2})^2}.$$
 The number of nodes within a distance $2^j$ of $t$ is $$1+4\sum_{d=1}^{2^j}d = 1 + 2(2^j(2^j-1)) = 1 + 2^{2j+1} - 2^{j+1} > 2^{2j-1}.$$
The number of nodes within a distance $2^j$ of $t$ is $$1+4\sum_{d=1}^{2^j}d = 1 + 2(2^j(2^j-1)) = 1 + 2^{2j+1} - 2^{j+1} > 2^{2j-1}.$$
Therefore, the probability that a long-range link exists that will reduce the phase is at least $$\frac{2^{2j-1}}{4\ln(6n) (2^{j+2})^2} = \frac{1}{128\ln(6n)}.$$
This statement is the crux of the argument. Notice that this estimate is independent of the current phase $j$: at each phase, we have a lower bound for the probability of leaving that phase that is independent of the phase. This justifies our earlier statement that the long-range links are distributed uniformly across all scales of resolution.
We may now estimate $T_j$, the amount of time we spend in phase $j$: $$\begin{eqnarray*} \overline{T}_j & = & \sum_{i=1}^\infty i~{\rm Pr}[T_j = i] \\ & = & \sum_{i=1}^\infty {\rm Pr}[T_j \geq i] \\ & \leq & \sum_{i=1}^\infty \left(1-\frac{1}{128\ln(6n)}\right)^{i-1} \\ & = & 128\ln(6n). \end{eqnarray*} $$
This shows that the average time spent in each phase is independent of the phase. Therefore, the average delivery time $\overline{T}$ satisfies: $$\overline{T} \leq (\log(n)+1)\cdot 128\ln(6n) \leq C\log(n)^2 $$
for some constant $C$. Small-world networks are characterized by the fact that the distance between any two points is not more than a polynomial in $\log(n)$. Since our algorithm finds paths having this property, we are assured that our algorithm finds suitably short paths. In other words, our network is searchable.
We have now shown that $\alpha=2$ leads to searchable small-world networks. A similar type of analysis shows that other values of $\alpha$ do not. Smaller values of $\alpha$ diminish the importance of geographic distance; the long-range links are too random to allow us to home in on the target. Larger values of $\alpha$ create too many shorter long-range links, which save relatively little time by following them.
Comments?
Putting our theory to the test
Kleinberg studies a family of small-world networks, parametrized by $\alpha$, and finds that only one gives a searchable small-world network, suggesting that searchable small-world networks exist in some delicate balance. Let's see how this corresponds with real-world data.
Liben-Nowell, Nowak, Kumar, Raghavan, and Tomkins tested this prediction by considering LiveJournal, a network of over a million bloggers each of whom publishes a profile containing his or her geographic location as well as a list of other LiveJournal users considered to be "friends." We may then construct a network consisting of the nearly half million users who give a location in the continental United States and use the published geographic information to determine the geographic distance $d(u,v)$ between two users.
Let's first ask whether this network satisfies the properties of a searchable small-world network. Users have, on average, eight friends, a relatively small number compared to other social networks. However, this network demonstrates a high clustering coefficient---when $u$ and $v$ have a friend in common, they are themselves friends roughly one-fifth of the time.
How does our searching algorithm perform? In a simulation, a randomly chosen source user $s$ attempted to send a message to a randomly chosen target user $t$. At each step, the current holder of the message $u$ sends it to the friend geographically closest to $t$. If $u$ has no friends closer to $t$, then the chain unsuccessfully ends. In a half million trials, the chain successfully concluded 13% of the time with an average delivery time just a little over four.
This study was then repeated after making a small modification; the current user $u$ was allowed to send the folder to a random friend if he or she had no friends closer to $t$. In this case, 80% of the chains completed with a median length of 12.
These results are illustrated in the following figure, in which the inset shows the results given the modified algorithm. The vertical scale represents $f(k)$, the fraction of completed chains having delivery time $k$.
|
Copyright 2005 National Academy of Sciences, U.S.A.
|
 |
From this, we may conclude that the LiveJournal network forms a searchable small-world network. Let's now look at the distribution of links and ask whether it follows Kleinberg's inverse-square relationship between probability and distance.
One problem needs to be addressed first. In Kleinberg's model, nodes are uniformly distributed in the plane; however, users in the LiveJournal network are not uniformly distributed across the continental United States. In the figure below, successive circles, each centered at Ithaca, New York, represent an increase of 50,000 nodes in the network. As we might expect, the nodes are more highly concentrated on the east and west coasts.
|
Copyright 2005 National Academy of Sciences, U.S.A.
|
 |
To this end, we will use rank to replace the role of distance in determining the probability that a link exists between two nodes. Given a node $u$, we define ${\rm rank}_u(v)$, the rank of $v$ with respect to $u$, to be the number of nodes that are closer to $u$ than $v$ is. For instance, in the figure below, ${\rm rank}_u(v)= 6$ since there are six nodes closer to $u$ than $v$ is (we include the node $u$ in this count).

If we consider two nodes $u$ and $v$ in the network placed on a uniform lattice and separated by a distance $d$, there are roughly $d^2$ nodes closer to $u$ than $v$ is. This says that the rank of $v$ is proportional to $d^2$. Our earlier analysis showed that we obtain a searchable small-world network when a link between $u$ and $v$ exists with probability proportional to $d^{-2}$. Expressed in terms of the rank, we therefore expect a link from $u$ leading to $v$ with probability proportional to ${\rm rank}(v)^{-1}$; this holds regardless of the dimension $k$ in which we create our lattice.
In fact, Liben-Nowell and his collaborators define a rank-based friendship network to be one in which the probability of a link between $u$ and $v$ is inversely proportional to ${\rm rank}_u(v)$: $$ {\rm Pr}[u\to v] \propto \frac{1}{{\rm rank}_u(v)}. $$
They then prove that the expected delivery time in a rank-based friendship network to be at most proportional to $(\log(n))^3$. In other words, rank-based friendship networks are searchable.
Liben-Nowell et al then looked at the LiveJournal network to determine whether it is a rank-based friendship network. The results are summarized in the figure below. Here we see the probability that a link exists between two nodes plotted as a function of the rank between the nodes. The quantity $\epsilon$ is what the authors call the "background probability," a component of the probability that is independent of geography and due to factors such as friendships forming online through shared interests.
|
Copyright 2005 National Academy of Sciences, U.S.A.
|
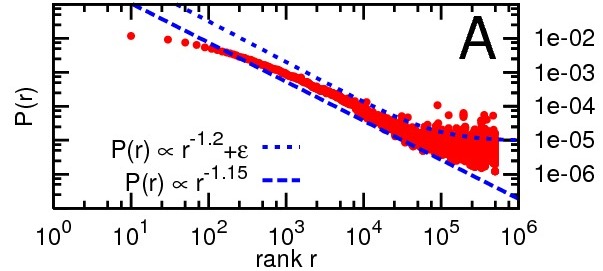 |
As can be seen, the probability and rank are very nearly inversely proportional to one another, as required for a searchable small-world network.
Below, we see the probability plotted as a function of the rank for the groups of LiveJournal users on the East and West Coasts of the United States. The inverse proportion is even more striking here.
|
Copyright 2005 National Academy of Sciences, U.S.A.
|
 |
As Liben-Nowell and his collaborators conclude: "In a lamentably imperfect world, it is remarkable that people form friendships so close to the perfect distribution for navigating their social structures."
Comments?
Summary
What we have seen is a rather remarkable story. Beginning with a mathematical model of Milgram's experiment, Kleinberg's analysis suggests that there is some underlying structure to the probabilitistic distribution of the links in a searchable small-world network. After refining the characterization of this distribution, Liben-Nowell et al then verified that one particular searchable real-world network closely matched this distribution.
Indeed, a similar analysis of Facebook, performed by Backstrom et al, again found the relationship between the distribution of links and rank to be very close to an inverse proportionality. There appears to be a remarkable agreement between real-world social networks and the simple models we have created to study them.
Finally, let us return to Milgram's original experiment. Our models have relied only on geographic distance as a means of determining the person to whom the folder is sent. Many participants indicated, however, that they sometimes chose their recipient based on occupation rather than geography. This suggests that it may be useful to consider models that include more dimensions so as to incorporate other factors such as occupation.
Indeed, this approach has been taken by Watts, Dodds, and Newman, who created a different model of a small-world network and showed that searchable networks become more common as more dimensions are added.
Thanks
I would like to thank David Liben-Nowell, who graciously shared the figures from the LiveJournal study with me, and the Proceedings of the National Academy of Sciences for permission to reprint them.
References
-
Stanley Milgram. The small-world problem, Psychology Today, Vol. 1, 60–67, 1967.
-
Lars Backstrom, Paolo Boldi, Marco Rosa, Johan Ugander, Sebastiano Vigna. Four Degrees of Separation, 2012. Available at http://arxiv.org/abs/1111.4570.
-
Duncan Watts, Steven Strogatz. Collective dynamics of 'small world' networks, Nature, Vol. 393, 440-442, 1998.
-
Jon Kleinberg. Navigation in a small world, Nature, Vol. 406, 845, 2000. Available at http://www.cs.cornell.edu/home/kleinber/nat00.pdf.
-
Jon Kleinberg. The small-world phenomenon: an algorithmic perspective. In Proc. 32nd ACM Symposium on the Theory of Computing, 163-170, 2000. Available at http://www.cs.cornell.edu/home/kleinber/swn.ps.
-
Jon Kleinberg. The small-world phenomenon and the dynamics of information. In Proc. 14th Advances in Neural Information Processing Systems, 431-438, 2001. Available at http://www.cs.cornell.edu/home/kleinber/nips14.pdf.
-
David Easley, Jon Kleinberg. Networks, Crowds, and Markets: Reasoning about a Highly Connected World, Cambridge University Press, 2010. Available at http://www.cs.cornell.edu/home/kleinber/networks-book/.
-
David Liben-Nowell, Jasmine Novak, Ravi Kumar, Prabhakar Raghavan, Andrew Tomkins. Geographic routing in social networks, Proceedings of the National Academy of Sciences, Vol. 102, no. 33, 11623-11628, 2005.
-
Ravi Kumar, David Liben-Nowell, Jasmine Novak, Prabhakar Raghavan, Andrew Tomkins. Theoretical Routing in Social Networks, Technical Report MIT-LCS-TR-990, MIT Press, 2005.
-
Lars Backstrom, Eric Sun, Cameron Marlow. Find me if you can: Improving geographical prediction with social and spatial proximity. In Proc 19th International World Wide Web Conference, 2010.
-
Duncan Watts, Peter Dodds, Mark Newman. Identity and search in social networks, Science, Vol. 296, no. 5571, 1302-1305, 2002.

 David Austin
David Austin