Crypto Graphics
Posted February 2010.
In this article, I'll just describe how to unpack the simplest outermost level of security...
Bill Casselman
University of British Columbia, Vancouver, Canada
cass at math.ubc.ca
Introduction
A new generation of `bar codes' is becoming ubiquitous, at least in the Western world. One principal motivation for this has been to foil counterfeiting, for example the counterfeiting of postage stamps. Many countries of Europe as well as Canada and the United States have implemented this scheme, although details vary from one country to the next.




In the near future, all pharmaceutical products sold in Europe will require similar authentication. There are other uses in packaging as well, although it is not clear to me what their purpose is.
In addition, correspondence from the IRS frequently includes data matrices but here, too, the purpose is not known to me.

Data matrices are not actually bar codes, which are one-dimensional. Instead, they (as well as nearly all of the new generation of similar code schemes) present a rather complicated 2D array. There are other candidates for 2D coding, but data matrices are among the most interesting. The advantage of 2D over 1D should be obvious - a 2D array can pack much more information in a small space. There is so much capacity, in fact, that there is room for extra bits of information to allow efficient error correction, which is a tremendous advantage. The largest allowable data matrix has dimensions 144 x 144, and allows 1558 bytes of message to be transmitted, with up to 620 errors correctable. This is an impressive amount of information. Looking at the sample images of postage stamps above, where cancellation and poor printing quality clearly causes trouble, will convince you that the system wouldn't be at all feasible without error correction.
In reading a data matrix, there are several layers that have to be peeled away and interpreted, and in many - for example postage and pharmaceutical authentication - the final layer to be seen is encrypted at the most sophisticated level of security currently available. In this article, I'll just describe how to unpack the simplest outermost level.
Assembling the bytes
Every data matrix encodes an array of bytes, which may roughly be considered as the smallest interpretable units inside computers. Each byte is an array of 8 bits, or in geometric terms 8 pixels. Colored pixels represent 1, uncolored represent 0. The basic interpretation of each byte is as a non-negative integer expressed in base 2. Since 2 8 = 256, it therefore represents a number in the range [0, 255]. Bytes in the lower half of this range are commonly interpreted more specifically as alphabetic, numeric, and other characters that appear on computer keyboards. How bytes in a data matrix are interpreted depends on context.
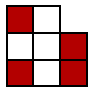
The first question, however, is how is the array of bytes to be found? I'll next answer this, and then suggest an explanation for what might appear at first to be an eccentric choice. The simplest feature of data matrices is that they are made up of one or more regions, each of which is bounded by a fixed pattern of pixels - solid at left and bottom, alternating coloured and blank at right and top. Most of the postage stamp examples are made up of 2 x 2 regions like this, although the presorted first class mail example is 1 x 2, and the ice cream carton matrix is made up of just one such region, as shown on the left below:

The point of these peripheral pixels or frame is to make it possible for devices intended to read the matrix to align themselves correctly. If the periphery is stripped away, we are left with the core pixels, which contain the real message (as on the right above). What remains to be done is locate the bytes making up the message. This is non-trivial, and depends on the dimensions of the data matrix. Nearly all bytes have the shape of a bitten square, and its bits are numbered right to left, bottom to top:
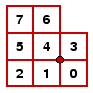
The byte at the left above therefore corresponds to the base 2 number 10001101, in decimal format 128 + 8 + 4 + 1 = 141. As suggested in the diagram at right, the origin pixel of a byte is at its lower right, corresponding to bit 0, and what I call its geometric origin is the point at the upper left of that pixel. The bytes are generally laid out in a lattice, starting at the upper left of the matrix. The counting always begins the same, no matter what the dimensions are. Right from the very beginning, however, bytes can fall outside the matrix. We'll see in a moment how to deal with that problem.
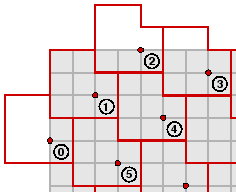
But after the first few bytes, how the bytes are located depends on the matrix dimensions. Here we see what happens for the ice cream carton. The nominal layout of bytes is shown at left below, the way in which bytes extending beyond the matrix are handled by wrapping around on the far side (generally with a shift) is shown in the middle, and the numbering of bytes is shown at right:

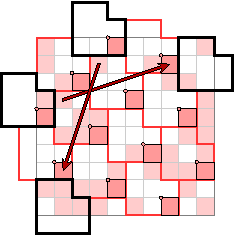
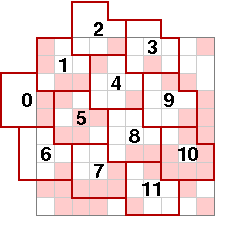
This makes the array of bytes to be 77, 163, 217, 130, 129, 158, 165, 15, 3, 65, 111, 68. We'll see later some idea of what that array means.
In general, the order in which the bytes are counted is by traversing alternately up and down along diagonals, moving roughly left to right. A byte is usually counted when its origin pixel is contained in the matrix, but as we shall see in a moment there are rare exceptions to this rule.
The allowable dimensions of matrices are limited to a list of 30. Most are square, but a few are rectangular. How bytes are located depends on the particular dimensions, but the layout of bytes (i.e. bitten squares) in the core matrix is periodic with period 8, so in fact this process reduces to a few small cases. Say r is the number of rows in the core matrix, c the number of columns. I'll look at square matrices first, for which r=c. If r = c = 0 modulo 8, there is absolutely no problem, as on the left below:
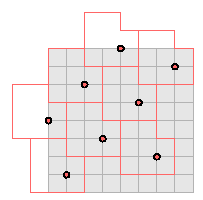
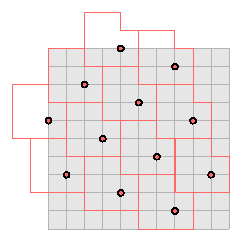
If r = c = 2 modulo 8, there is only a minor problem. The number of pixels rc is not divisible by 8, so there have to be pixels that are not associated to any byte. These occupy the 2 x 2 square at the lower right of the matrix, as on the right above.
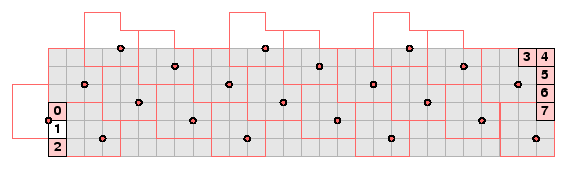
If r = c = 4 or 6 modulo 8, then there is no completely clear way to assign the location for exactly one of the bytes, no obvious way to assign bits within that byte, and no obvious way to assign the order of the exceptional byte in the total array. In each of the figures below, a candidate nominal origin pixel is uncolored, the ordering is indicated by a colored origin circle, and the bit order within the exceptional bytes (rather arbitrary) is also shown. Thus in both matrices just below the exceptional byte is number 8.


The same problem occurs for rectangular matrices as well. On the left below the exceptional byte is the last one, and on the right it is the first.

The way in which bytes are stored as bitten squares might seem a bit peculiar, but if you think about how errors occur in the transmission of data matrices (for example poor printing, postage cancellation), it makes sense. The scheme is designed so that the minimum number of bytes are affected by such errors. Other features (the funny way in which `unrandomization' is applied) are not so clearly advantageous, and are pretty much a mystery to me.
Interpreting the bytes
The second question now is how is the array of bytes now assembled to be interpreted? The first thing to realize is that the last several bytes are part of the error correction mechanism, and the remaining initial segment is the message transmitted. Exactly how many are error correction bytes depends on the dimensions of the matrix - for a 12 x 12 matrix there are 12 bytes in all, 5 of which make up the message and 7 of which are for error correction. (For larger matrices the ratio is more satisfactory.) The error correction bytes are used to check if the message has been distorted, and if so, they can be used to correct the error to some extent. After this stage, one is left with the message itself. For this, there are several different modes of interpretation. I'll discuss just exactly two, which seem to be the most common ones.
ASCII mode. This is the default mode - every data matrix starts off in this mode. How to interpret some of the bytes in the range [0, 255] is shown in the table below. Roughly speaking, bytes in the range [0,128] are interpreteted as ASCII characters, those in the range [130,229] are interpreted as two-digit numbers, and many of the rest as indicating a shift to another mode.
|
Byte bn
|
Interpretation of bn
|
|
1 - 128
|
as ASCII character bn-1
|
|
129
|
the first character of padding that will continue to the end of the message
|
|
130 - 229
|
pair of digits 00 - 99 with numerical value bn - 130
|
|
231
|
escape to BASE256 mode
|
Following a byte bn = 231 are one or two bytes indicating the length of the segment to be read in BYTE256 mode. Exactly how the bytes of the segment of BYTE256 mode, including its length, are to be read is curiously technical, as we'll see a bit later.
At any rate, following this scheme, let's look at the message on the ice cream carton, which is the sequence of 5 bytes 77, 163, 217, 130, 129. The last byte is padding, so the message is really only 4 bytes. The first byte 77 is in the low range, so to be read as ASCII character L. The next three are in the range of two-digit numbers, so to be read as 163-130 = 33, 217-130 = 87, and 130-130 = 0. But what significance the sequence M, 33, 87, 0 has to anyone is a mystery to me. This is common enough in this sort of thing - data matrices are often meant to have obscure significance apparent only to a select few. In the case of postal systems and pharmaceutical products, the final message is to be interpreted according to the rules of one-way public key crytography, so that authenticity may be checked but not counterfeited.
BASE256 mode. In this mode, there is no special meaning to any of the possible bytes - interpretation is up to the user. Becuase of this, there is no way to tell when the segment has come to an end, and the length of the segment in this mode must be specified at the start.
There is one trick used throughout this mode, including the one or more bytes indicating this length, called unrandomized 255 reading. In this mode of reading, byte bn is converted to another byte vn according to the formulas
|
r = ((149*(n+1)) modulo 255) + 1
vn = (bn-r) modulo 256
|
Here is what happens after a 231 in ASCII mode: (1) the next byte bn is read and converted to vn according to this unrandomization process. If this is < 250, then the length of bytes to be interpreted in BYTE256 mode is just vn. But if vn ≥ 250, we get the next value vn+1 as well. The length is then (vn - 249).250 + vn+1.
Let's look at an example. Suppose the byte array of a data matrix reads 231, 63, 40, 198, 96 ... The byte b0 = 231 means that we are immediately put into BYTE256 mode. The next byte b1 = 63 is converted by unrandomization:
|
r = (149.2 + 1) = 44 (mod 255)
v1 = 63 - 44 = 19
|
(where the dots represent multiplication). Therefore we are now to read 19 bytes in BASE256 mode. The byte v2 is calaculated:
|
r = (149.3 + 1) = 193
v2 = 40 - 193 modulo 256 = 103
|
which in this particular message is to be converted to the ASCII character g. The next byte b3 is converted to o, the next b4 to t, etc.
A conversion to BASE256 mode is commonly encountered, in particular with all postal systems I have looked at.
To find out more ...
- The Wikipedia entry http://en.wikipedia.org/wiki/Barcode offers a useful survey of various kinds of bar codes, in particular a nice collection of images of various types.
- Japan has generally adopted a variant 2D code known as QR code. It has achieved some notoriety, as you can see from the world's largest QR code symbol and what can apparently be found in cemeteries.
- Gerrit Bleumer, Electronic postage systems: technology, security, economics, Springer, 2007.
This is the only printed book that I know of that discusses the postal use of data matrices. The Royal Mail web site illustrates one modern use of data matrices in postage, and the Deutsche Post web site illustrates another.
- As far as low-level reading of data matrix symbols goes, one thing that is presumably essential for professional work is the ISO specification, which you can find by searching for ISO/IEC 16022-2006 at http://www.iso.org/iso/ but it costs real money (224 Swiss francs!), and I have not had a chance to see it.
- The Wikipedia entry for data matrix at http://en.wikipedia.org/wiki/Data_ matrix_(computer) is helpful, but doesn't have much detail.
- The web page http://www.bcgen.com/datamatrix-barcode-creator.html has an interactive application that will allow you to create data matrix symbols from text you type in. As far as technical details are concerned, links to pages on data matrices can be found at http://grandzebu.net/
Follow links to the English version of barcodes, then to `data matrix'.
- Another good source of information is http://www.libdmtx.org/, which provides programs in C for reading and writing data matrices. This combined with the grandzebu site makes a fairly practical source for programming.
- The 12 x 12 symbol on the ice cream carton has analogues on other groceries, as you can see at http://www.flickr.com/photos/nickj365/. Is there a single company ultimately responsible for this phenomenon?
Bill Casselman
University of British Columbia, Vancouver, Canada
cass at math.ubc.ca
Those who can access JSTOR can find some of the papers mentioned above there. For those with access, the American Mathematical Society's MathSciNet can be used to get additional bibliographic information and reviews of some these materials. Some of the items above can be accessed via the ACM Portal , which also provides bibliographic services.




