How Much Longer Can This Go On?
Posted June 2009.
How can we systematically find the longest increasing subsequence?
Bill Casselman
University of British Columbia, Vancouver, Canada
cass at math.ubc.ca
Introduction
Suppose given a sequence of distinct numbers, and we ask, what is the length of the longest increasing subsequence?
For example, I give you
Trial and error give you almost immediately several subsequences of length 3, such as 2, 5, 7. In fact, it's easy to write down all those of length 3:
2, 5, 7
2, 5, 6
2, 4, 7
2, 4, 6
1, 4, 7
1, 4, 6 |
So the question quickly becomes, are there any of length 4? Well, any subsequence of length 4 would have to extend one of length 3, so you can just look at all of length 3 and see if any can be extended. The answer is, no.
So if you think only of short sequences, this will seem easy to answer. I'll demonstrate a graphical method that will help you do the necessary mental calculation quickly. But suppose I give you a sequence of 100 numbers
| 41, 93, 31, 73, 98, 29, 12, 54, 24, 0, 52, 78, 87, 55, 25, 81, 76, 91, 51, 7, 39, 92, 65, 40, 45, 5, 1, 20, 84, 99, 27, 32, 13, 8, 2, 61, 19, 9, 74, 60, 66, 79, 47, 86, 30, 3, 85, 42, 89, 43, 70, 17, 6, 63, 28, 11, 34, 75, 22, 64, 59, 16, 48, 15, 90, 80, 69, 67, 35, 72, 50, 14, 33, 53, 10, 38, 94, 18, 58, 46, 49, 88, 68, 21, 62, 44, 97, 82, 37, 83, 95, 4, 56, 57, 77, 23, 96, 26, 36, 71 ? |
Answering this question will involve a few digressions, and will have connections to many parts of mathematics. In the first part of this column, I'll explain how to solve the problem posed here, very little more and no less. In the second, I'll say something about extensions into other matters.
Note: The original posted column was mathematically incorrect (near the end of the Heights section). I wish to thank Luigi Rivara for pointing this out. What follows is now correct.
Part I. Increasing subsequences
Reformulation
So, suppose we are given a sequence of n distinct integers. It will make things slightly, but not drastically, simpler if we look only at sequences of n integers in the range 0 ... (n-1). In effect we are given a rearrangement or permutation of this range. How can we systematically find the longest increasing subsequence? Let's look at something easier than one of length 100, say this one
It will make the discussion easier, if we add to this list the indices of the numbers in the sequence, starting with 0, so it becomes a sequence of pairs of numbers, which can be written
| |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| |
5 |
2 |
0 |
6 |
1 |
4 |
7 |
3 |
The original problem can now be formulated slightly differently. We are going to put an order on pairs of numbers. Define (a,b) ≤ (c,d) to mean that a ≤ c and b ≤ d. (This is what is called a partial order, because it can happen that of two given pairs, neither is less than or greater than the other. For example, [2,5] and [4,1] are not comparable.)
We are given a set of such pairs
| |
[0,5] |
[1,2] |
[2,0] |
[3,6] |
[4,1] |
[5,4] |
[6,7] |
[7,3] |
and we want to find in it a constantly increasing chain of greatest length. We can picture the problem. In the following figure the pairs are marked in red, and one pair is `smaller' than another when there is a chain of arrows from the first to the second.
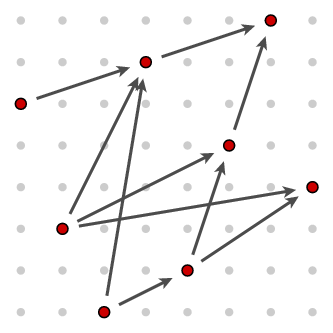
It is easy to read off from the diagram that the length of a maximal chain is 4, and that there is exactly one of that length, starting at [2,0] and ending at [6,7].
Heights
The diagram also suggests a way to solve the problem systematically.
(1) Certain pairs are minimal in the set - there are no smaller pairs. In the diagram, these are the ones that are in some sense 'at lower left'. Here there are three of them: [0,5], [1,2], and [2,0], all marked in red in this diagram:
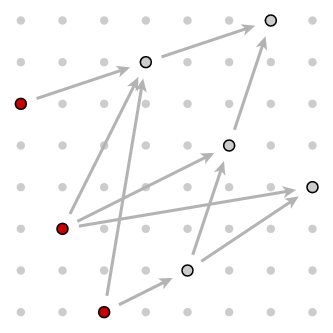
To be precise, recall that the order on our set of pairs is given by arrows, and one pair is less than another if there is a chain of arrows from the first to the second. A pair is minimal if there are no arrows with it as target. So we can find the minimal pairs by running through all the arrows, and eliminating their targets.
More generally, suppose we call the height of a pair one more than the length of the longest increasing chain ending at it. The minimal pairs are those of height 0. And we have now found a new way to formulate the original problem - we want to find a pair with the largest possible height. Here are the height assignments, which we find by inspection:
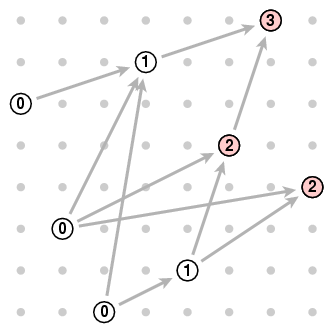
The colored pairs are a bit more interesting than the others. You may at first be tempted to say, if we want to assign a height to some pair [x,y] and we have an arrow from a pair [a,b] of height 0 to it, then we assign it height 1. But this would be wrong, say, for the pair [5,4]. The longest path to it comes from [4,1], which has height 1, so we assign it height 2.
The basic principle for any set of pairs is that a pair (x,y) has height h if (a) there is a pair of height h-1 which is less than (x,y) and (b) there are no smaller pairs of height ≥ h. Why is this? Well, a pair of height h-1 has to it a chain of length h, so (a) guarantees that there is a chain to (x,y) of length h+1, and its height is at least h. As for condition (b), if [x,y] were assigned height ≥ h+1 there would be a chain to it of length ≥ h+2, and in that chain just before it a pair of height ≥ h. So there would have to be some pair of height h that is smaller than [x,y].
These criteria are practical. It might seem with condition (b) that we are just going around in circles, but in fact there is a fairly simple way to assign heights as we read from left to right. (1) The very first pair in the list has to have height 0, it is guaranteed to be minimal. (2) Suppose we want to assign height to a pair [i,n] and we have already assigned heights to all previous pairs. Any pair smaller than the current pair [i,n] has to be one of the previous pairs. So we scan them to check conditions (a) and (b).
For example, let's look at our example again. Suppose we have assigned heights for the first five pairs, and want to find the height of the sixth pair [5,4]..
| |
Index |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| |
Number |
5 |
2 |
0 |
6 |
1 |
4 |
7 |
3 |
| |
Height |
0 |
0 |
0 |
1 |
1 |
2 |
|
|
In order to check whether a previous pair is smaller, it is enough to check that the second coordinate is smaller, since the first one is necessarily so. The previous pairs smaller than [5,4] can be read easily as [1,2], [2,0], [4,1]. The first two are of height 0, but the second is of height 1. So the height of [5,4] is 2.
Here are the final height assignments:
| |
Index |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| |
Number |
5 |
2 |
0 |
6 |
1 |
4 |
7 |
3 |
| |
Height |
0 |
0 |
0 |
1 |
1 |
2 |
3 |
2 |
I summarize how the process goes: We scan through the sequence from left to right, finding for each i in succession the height hi of ni . In finding hi , we scan through all the prior items nj < ni , finding the maximum height hj among them. Then we set hi = hj + 1. This calculation even tells us, recursively, how to assemble for each i a chain of maximal length ending at ni, since it gives us for each ni an nj just prior to it in a maximal increasing chain.
The obvious drawback of this process is that it is horribly inefficient, since in assigning hi we have to search through all i-1 predecessors. The amount of work involved is thus proportional to 1+ 2 + 3 + ... (n-1) = n(n-1)/2 for a sequence of length n. For n large, this is roughly n2/2; for n=100 about 5,000, not feasible to do by hand.
Organization
Is it really necessary to scan through all nj with j < i when assigning hi ?
If you think carefully about what's going on, you see that there are two criteria to be satisfied when assigning height h to ni :
| |
(1) |
ni < all predecessors nj with hj ≥ h ; |
| |
(2) |
ni > at least one predecessor nj with hj = h-1 ; |
But these suggest that as we go along we keep track of some extra data - for each height h we keep track of the minimum value of nj among those j with hj = h. With these data at hand, we no longer have to scan the entire list of predecessors, but need just to scan down the list of such minimum values to find the smallest one that is still greater than ni.
We can understand this better if we maintain a record of all the items with a given height, which I'll do in a kind of bar graph. If the original sequence we are considering is the one above - i.e.
then the graphs go like this:

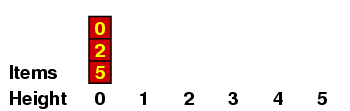

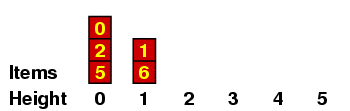
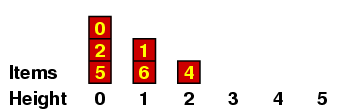
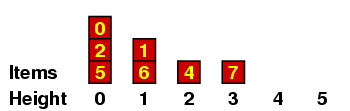
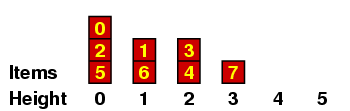
Let me explain a few of these. (a) When we are placing the 2, we have no predecessors of size < 2, so it gets height 0. (b) When we are placing the 6, there are several of size < 6, all of height 0, so it gets height 1. (c) When we are placing the 3, it is < 7 so it can't have height 4 ; and it is < 4, so it can't have height 3 ; but it is > 1, which has height 1, so it gets height 2.
This procedure is much, much better than the original one. It costs a little extra effort to keep the height records, but the amount of time it takes to assign all heights is very roughly proportional to the length of the input sequence.
The sequence of 100 integers written down at the beginning is entirely feasible. We get the length of a longest subsequence to be 15, and a subsequence of that length to be
| |
9 |
26 |
34 |
45 |
52 |
55 |
71 |
72 |
75 |
79 |
80 |
92 |
93 |
94 |
95 |
| |
0 |
1 |
2 |
3 |
6 |
11 |
14 |
33 |
38 |
46 |
49 |
56 |
57 |
77 |
96 |
Furthermore, we can streamline things even a bit more. We don't have to keep records of all the items of given height, because as these records grow, the items on top of the record decrease. (I leave it as an exercise to figure out why.) This means that the top item of each record is the always the minimum of that height, and after all that's all we need. So we only have to keep a list of the last item assigned a given height. This leads to the bumping algorithm.
Bumping
The way this computation is usually explained is in terms of the bumping algorithm. We are given a sequence of N distinct numbers ni and want to find the longest increasing subsequence. We start with an empty array h indexed by -1 ... N. We initialize it by setting h-1= -∞ and hi = ∞ for all i ≥ 0.
We then progress through the sequence n0, n1, ... modifying the array h as we go along. In terms of the process we described before, at any given moment the j-th item in h will be the previous item we saw of height j. In order to assign a height to [i, ni], we find j with the property hj < ni < hj+1 , and replace hj+1 by ni (i.e. we bump hj+1), to which we assign height j+1. Initializing with -∞ and ∞ saves us some trouble dealing with special cases.
Here's how the array changes with time in the example above.
| |
h0 |
h1 |
h2 |
h3 |
|
|
| |
∞ |
|
|
|
|
5,2,0,6,1,4,7,3 |
| |
5 |
|
|
|
|
2,0,6,1,4,7,3 |
| |
2 |
|
|
|
|
0,6,1,4,7,3 |
| |
0 |
|
|
|
|
6,1,4,7,3 |
| |
0 |
6 |
|
|
|
1,4,7,3 |
| |
0 |
1 |
|
|
|
4,7,3 |
| |
0 |
1 |
4 |
|
|
7,3 |
| |
0 |
1 |
4 |
7 |
|
3 |
| |
0 |
1 |
3 |
7 |
|
|
Following this as described doesn't tell us as much as does the earlier process of assigning heights in place to the numbers in the sequence, but it does tell us that the maximum height is 3. At each stage, we have to search the array H to find where to insert something. This can be done (by binary search) in a number of steps proportional to the logarithm of the length of the array. The amount of time it takes to finish the process is therefore proportional to at most n log n if the length of the original sequence is n - much faster than one might expect from a first look at the problem. In doing this by hand, the part that takes the longest is just writing stuff down.
Part II. Going further
Recycling
The bumping process is rather wasteful. When one inserts an item into the array to replace an item that is already there - when we bump it - we have not paid any attention at all to the item we replace. Is it really necessary just to throw away all those bumped items? Not at all! They can be reused! We build up a new sequence of pairs from the bumped items. If hj < ni < hj+1, we bump hj+1 and replace it by ni. But now instead of just forgetting hj+1, we add the pair [i,hj+1] to a new sequence of pairs to be dealt with in the next stage. In the example above, [1,2] bumps 5; [2,0] bumps 2; [4,1] bumps 6; and [7,3] bumps 4. So the new sequence of pairs we get is [1,5], [2,2], [4,6], [7,4].
We insert this into a new blank row. The row becomes 2,4, giving in turn a bumped sequence [2,5], [7,6]. Repeat. If we write the succesive rows underneath each other, we get finally the pattern
This pattern is called a tableau. It has this characteristic feature: the numbers in rows increase from left to right, and those in columns increase from top to bottom.
So far, we haven't done anything with the first coordinates we carry along. Now what we do is maintain at each stage two rows simultaneously, getting eventually two tableaux of the same shape. Whenever a number is added to the first row instead of replacing a number already there, we place the index of the number inserted to the second row. What we get in this example is a similar tableau:
Going backwards
The process of going from the initial sequence through a sequence of pairs to a pair of tableaux can be reversed. For example, suppose we are given the tableaux
We can read off from this what has happened. The last entry added to the tableaux had to be the 4 in the second one. So the last entry made in the first was in the same location. So the 4 in the second row was bumped from the first row, and in fact it had to be bumped by the 3. So the last operation done was to insert 3 into the first row of the following pair of tableaux.
Continuing, we see that the previous operation was to insert a 4. In the end, we can see that the initial sequence of numbers was 1, 2, 0, 4, 3.
The Robinson-Schensted correspondence
Since we can go both ways - sequence to pair of tableaux and back again - we get in the end a matching of permutations of 0 ... (n-1) with pairs of tableaux of n elements each. This turns out be a remarkable way to understand permutations. This topic has generated a huge amount of mathematics research.
To find out more ...
- W. Fulton, Young tableaux, Cambridge University Press.
Chapters 1 - 4 are all about the same topic. I prefer a less abstract approach, but this is easy to read and full of examples.
- C. Greene, Some partitions associated with a partially ordered set, Journal of Combinatorial Theory 29 (1976), 69 - 79.
This is one simple way in which the approach described here can be extended. Greene's algorithm finds maximal increasing chains in arbitrary finite partially ordered sets.
- D. E. Knuth, Permutations, matrices, and generalized Young tableaux, Chapter 31 of Selected papers on discrete mathematics. Original to be found in Pacific Journal of Mathematics 34 (1970), 709-727.
This has many insights not to be found elsewhere in the literature.
- D. E. Knuth, The Art of Computer Programming Volume III, section 5.1.4 on Tableaux and involutions.
This is perhaps the best place to start in learning more about the correspondence between permutations and tableaux.
- C. Schensted, Longest increasing and decreasing subsequences, Canadian Journal of Mathematics 13 (1961), 179-191.
I believe this to be the first place where the problem of longest increasing subsequence was attacked by the methods explained here. But Knuth's paper is clearer.
- J-Y. Shi, The Kazhdan-Lusztig cells in certain affine Weyl groups, Lecture Notes in Mathematics 1179.
The partition of the group of permutations into pieces according to the shape of the corresponding tableau is part of a much larger topic, one in which research is still active. This is perhaps the single best place to start learning about it. Much of Shi's book is concerned with extending Schensted's algorithm to some infinite groups. The ideas introduced in the paper by Greene mentioned above play an important role.
- J. Michael Steele, Variations on the monotone subsequence theme of Erdős and Szekeres, in Discrete Probability and Algorithms, edited by Aldous, Diaconis, and Steele. Published by Springer, 1995.
One of the most interesting questions in this topic is, what is the average length of a maximal increasing subsequence in a sequence of n numbers? The answer is, about 2 √ n. This article discusses this and other related matters.
- Wikipedia entry on longest increasing subsequence.
Bill Casselman
University of British Columbia, Vancouver, Canada
cass at math.ubc.ca
Those who can access JSTOR can find some of the papers mentioned above there. For those with access, the American Mathematical Society's MathSciNet can be used to get additional bibliographic information and reviews of some these materials. Some of the items above can be accessed via the ACM Portal , which also provides bibliographic services.


