A month ago, I was playing the card game Crazy Eights with one of my children. During the middle of one game, we went through the entire deck, so we shuffled the cards in the discard pile a few times and started playing again. Hmmm. The cards were still grouped too closely by suits; that is, in spite of the shuffles, we were still seeing long sequences of, say, clubs when drawing from the pile. The ordering from the first part of the game persisted after the shuffles; it would seem that the shuffles hadn't affected the ordering of the deck as much as we wished.
This led me to wonder how many shuffles would be needed to give a good guarantee that the deck had been put in random order. Curiously, I soon came across an essay in Aigner and Ziegler's wonderful book Proofs from the Book that addressed just this issue and that led me to a remarkable paper by Aldous and Diaconis that gives an answer to this question.
This column will explain a few of the techniques and results from that paper. What is surprising is that a mathematical analysis of this seemingly innocuous question is linked to a wide range of mathematical questions, in areas such as Lie algebras, Hochschild homology, and random walks on graphs, and has been generalized in significant ways.
Let's begin by supposing that we have a deck of $n$ cards; to keep things simple, we will assume that the cards are decorated only with the numbers $1$ to $n$. Initially, the cards are in numerical order and we will shuffle them using some technique that we agree upon. The usual shuffle is called a riffle shuffle and will be discussed later. For now, we'll begin with a simpler type of shuffle called the top-in-at-random shuffle. In this shuffle, we remove the top card from the deck and place it, with equal probability, in any of the $n$ available positions.

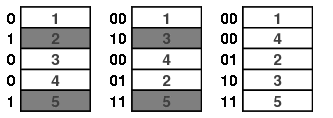
For instance, with $n=3$, there are three possibilities, each of which is equally likely.

Let's be quantitative about this shuffle. The set of all orderings of the deck will be denoted by $S_n$, which is often called the symmetric group on $n$ letters. There are $n!$ possible orderings. If $\pi$ is a particular ordering of the deck, we will denote the probability that $\pi$ is obtained after one shuffle by $Q(\pi)$.
Consider the example above in which $n=3$. If we write the ordering of the deck from left to right, we see that
| $\pi$ |
$Q(\pi)$ |
| 1 2 3 |
0.333 |
| 1 3 2 |
0.000 |
| 2 1 3 |
0.333 |
| 2 3 1 |
0.333 |
| 3 1 2 |
0.000 |
| 3 2 1 |
0.000 |
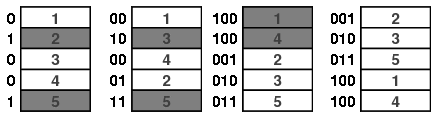
This shows that three of the six possible orderings are equally likely, and the other three are not at all possible. So we shuffle again ... and again. The possible orderings of the deck are shown below after 1, 2, and 3 shuffles. For convenience, the cards are here represented by colors rather than numbered.

By $Q^k(\pi)$, we will mean the probability that the ordering $\pi$ occurs after $k$ shuffles. A little computation shows that
| |
$Q^1(\pi)$ |
$Q^2(\pi)$ |
$Q^3(\pi)$ |
$Q^4(\pi)$ |
$Q^5(\pi)$ |
$Q^6(\pi)$ |
$Q^7(\pi)$ |
$Q^8(\pi)$ |
$Q^9(\pi)$ |
$Q^{10}(\pi)$ |
| 1 2 3 |
0.333 |
0.222 |
0.185 |
0.173 |
0.169 |
0.167 |
0.167 |
0.167 |
0.167 |
0.167 |
| 1 3 2 |
0.000 |
0.111 |
0.148 |
0.160 |
0.165 |
0.166 |
0.166 |
0.167 |
0.167 |
0.167 |
| 2 1 3 |
0.333 |
0.222 |
0.185 |
0.173 |
0.169 |
0.167 |
0.167 |
0.167 |
0.167 |
0.167 |
| 2 3 1 |
0.333 |
0.222 |
0.185 |
0.173 |
0.169 |
0.167 |
0.167 |
0.167 |
0.167 |
0.167 |
| 3 1 2 |
0.000 |
0.111 |
0.148 |
0.160 |
0.165 |
0.166 |
0.166 |
0.167 |
0.167 |
0.167 |
| 3 2 1 |
0.000 |
0.111 |
0.148 |
0.160 |
0.165 |
0.166 |
0.166 |
0.167 |
0.167 |
0.167 |
Notice that as we perform more shuffles, the frequency with which we see the different orderings becomes more uniform. By $U(\pi)$, we will denote the probability density in which each ordering $\pi$ is equally likely; that is, $U(\pi) = 1/n!$ The results in the table above indicate that
\[Q^k \to U \quad\hbox{as}\quad k\to\infty. \]
To make this statement precise, and to faciliate a quantative analysis of shuffling, we need to introduce a notion of distance between probability densities. Therefore, suppose that $Q_1$ and $Q_2$ are two probability densities on $S_n$. First, we define the difference in $Q_1$ and $Q_2$ for $A$, a subset of $S_n$, by adding together the differences over all the elements of $A$:
\[ \|Q_1(A)-Q_2(A)\| = \frac{1}{2}\sum_{\pi\in A}|Q_1(\pi) - Q_2(\pi)| \]
Then the distance between $Q_1$ and $Q_2$ is the maximum distance over all the subsets of $S_n$:
\[ \|Q_1-Q_2\| = \max_{A\subset S_n} |Q_1(A) - Q_2(A)| \]
Note that this is a very sensitive measure of the distance between the two densities. First, notice that $0 \leq \|Q_1-Q_2\| \leq 1$. Next, imagine that $U$, the uniform distribution on $S_n$, and $Q$ is a density resulting from a particular type of shuffle. If this type of shuffle leaves a single card in its original place, then
\[ \|Q-U\| = 1 - \frac{1}{n}, \]
which is a rather large distance considering that the maximum distance between sets is 1.
You may wish to check that the distance between the initial distribution $I$, which has $I(1 \thinspace 2\thinspace\ldots n) =1$ and $I(\pi) = 0$ for all other orderings, satisifies:
\[ \| I - U \| = 1 - \frac1{n!}\]
With this definition, our example indicates that $\|Q^k - U\| \to 0$ as $k\to\infty$, which means that shuffling the deck using top-in-at-random shuffles will eventually produce all orderings of the deck with equal probability.
Strong uniform stopping rules
Given a technique for shuffling the deck, and its resulting probability density function $Q$, we would like to be able to estimate how far away from the uniform distribution we are after $k$ shuffles; that is, we would like to understand the distance $\|Q^k - U\|$.
The notion of a strong uniform stopping rule gives us a tool for understanding this distance. First, imagine that we look at each shuffle in a sequence of shuffles and that we have a criterion that stops the sequence when satisfied.
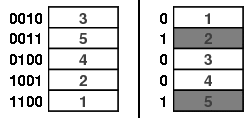
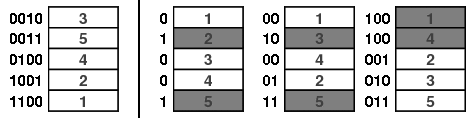
For example, imagine that we have a sequence of top-in-random shuffles and that we stop the sequence when the card that was originally at the bottom of the deck (and labeled by $n$) rises to the top and is then inserted somewhere in the deck.
This is illustrated below for the case $n=3$. The bottom card is shown in red so we stop the sequences at the orderings in the gray box.

We call such a criterion a strong uniform stopping rule if when the sequence is stopped after $k$ shuffles, then the resulting orderings are uniformly distributed. As a little thought shows, the rule described above for top-in-at-random shuffles satisfies this condition since at every step the ordering of the cards below card $n$ is uniform. This is apparent, for the case $n=3$ and $k=3$, in the figure above.
Why are strong uniform stopping rules useful? The following remarkable fact explains.
|
Suppose that $T$ denotes the stopping time for a sequence of shuffles and $P(T> k)$ denotes the probability that the stopping time of a sequence is larger than $k$. Then we have the following bound on the distance beween $Q^k$ and $U$:
\[ \|Q^k - U \| \leq P(T>k).\]
|
In other words, this reduces the problem of comparing the distance between the density after $k$ shuffles and the uniform density to an analysis of the stopping time. As we'll see, this can be a much simpler problem.
Where does this bound come from? It's fairly straightforward. Remember that the distance $\|Q^k - U\|$ is defined by looking at the difference in the densities on subsets $A$ of $S_n$. By $X_k$, we will denote the ordering that results from shuffling $k$ times.
We'll begin by noting that we may partition the sequences of shuffles in which $X_k$ is in $A$ by their stopping times:
\[ Q^k(A) = \sum_{j\leq k} P(X_k \in A \thinspace{\rm and} \thinspace T = j) + P(X_k\in A \thinspace{\rm and}\thinspace T > k) \]
We will rewrite both of the terms on the right. Consider the first term: here's where we use the fact that the orderings that result from a fixed stopping time are uniform:
\[ \sum_{j\leq k} P(X_k \in A\thinspace{\rm and}\thinspace T = j) = \sum_{j\leq k} U(A)P(T=j) = U(A)(1-P(T>k)). \]
We will rewrite the second term using the conditional probability:
\[ P(X_k\in A\thinspace{\rm and}\thinspace T>k) = P(X_k\in A | T > k) P(T>k) \]
Combining these two expressions gives
\[ Q^k(A) = U(A) + \left(P(X_k\in A | T>k) - U(A)\right) P(T>k), \]
which is the same as saying
\[ Q^k(A) - U(A) = \left(P(X_k\in A | T>k) - U(A)\right) P(T>k). \]
Now since $P(X_k \in A | T>k)$ and $U(A)$ are both probabilities, their values are between 0 and 1. Therefore, the absolute value of their difference is as well as we obtain:
\[ \|Q^k(A) - U(A)\| \leq P(T>k). \]
Since this holds for every set $A$, we obtain the desired bound:
\[ \|Q^k-U\| \leq P(T>k). \]
Riffle shuffles
Armed with this tool, we may study how fast a particular shuffling process converges to the uniform distribution by finding a strong uniform stopping rule and determining the probability that the stopping time is larger than $k$. We will apply this tool to a study of riffle shuffles, which model the usual way in which a deck of cards is shuffled.
To perform a riffle shuffle, we choose $c$ cards from the top of the deck according to the binomial distribution. That is, the probability that we choose $c$ cards is $$\frac{1}{2^n}{n\choose c}.$$
We hold these cards in our left hand and the other $n-c$ cards in our right. A card now falls from either our left or right hand with the probability that the card falls from one hand being proportional to the number of cards in that hand.
|
This description models the physical act of shuffling cards. However, an alternate way to describe this shuffle is like this: choose the $c$ cards off the top according to the binomial distribution. For instance, here we choose $c=3$ cards.
|
 |
|
Now choose, with equal probability, a set of $c$ positions within the deck of $n$ cards.
|
 |
|
Place the chosen cards, in order, in these positions, and the remaining $n-c$ cards, in order, in the other positions.
|
 |
We will denote by $R$ the probability density on $S_n$ defined by one riffle shuffle. We wish to study $R^k$, the density that results after $k$ riffle shuffles, and determine when it is sufficiently close to the uniform density to consider the deck well shuffled.
|
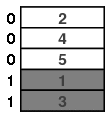
It turns out that it is easier to answer this question by considering what happens when we undo a riffle shuffle. To do this, simply walk through the deck labeling every card, with equal probability, with a "0" or "1."
|
 |
|
Then use the labels to divide the cards into two ordered groups and place the group labeled "0" on top.
|
 |
This results in the inverse riffle shuffle:
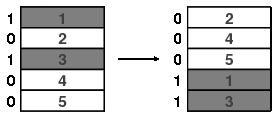
The probability density $\overline{R}$ defined by the inverse riffle shuffle is the same distance from the uniform distribution as the original riffle shuffle. To see this, think of $\pi$, an ordering of the cards, as defining a permutation of the $n$ cards. If $\overline{\pi}$ is the inverse permutation, then we have $\overline{R}(\pi) = R(\overline{\pi})$. Given a set of permutations $A$, we will let $\overline{A}$ be the set of inverses of $A$. We therefore have
\[ \|\overline{R}^k(A) - U(A)\| = \|R^k(\overline{A})-U(\overline{A})\|, \]
which implies that $\|\overline{R}^k - U\| = \|R^k-U\|$.
A stopping rule for inverse riffle shuffles
Now that we have seen that the densities defined by inverse riffle shuffles lie the same distance from the uniform density as those defined by riffle shuffles, we would like to develop a strong uniform stopping rule for inverse riffle shuffles. But first, let's describe a means of enumerating inverse riffle shuffles.
Suppose we perform a sequence of $k$ inverse riffle shuffles. In each shuffle, each card is labeled with a "0" or a "1." If we concatenate the labels from each shuffle, then each card is labeled with a string of $k$ 0's and 1's. (We usually call such strings $k$-bit strings.)
To summarize, a sequence of $k$ inverse riffle shuffles defines an ordering of the $n$ cards as well as a set of $n$ $k$-bit strings. Conversely, if we choose an ordering of the cards $\pi$ and a set of $n$ $k$-bit strings, we may define a sequence of $k$ inverse shuffles: begin with the standard ordering of the cards and perform inverse shuffles, based on the appropriate bit:
The ordering on the deck of cards that results is $\pi$.
The stopping rule is simple: stop when the cards have distinct labels. To see that this is a strong uniform stopping rule, simply notice that the choices of an ordering $\pi$ and a set of $n$ $k$-bit strings are independent. Therefore, if $B$ is a set of distinct $k$-bit strings and $\pi_1$ and $\pi_2$ are two orderings of the deck, then $(\pi_1,B)$ and $(\pi_2,B)$ give two sequences of inverse riffle shuffles that are equally likely and that lead to $\pi_1$ and $\pi_2$, respectively. Therefore, we are just as likely to see $\pi_2$ as $\pi_1$ as a result of a sequence of inverse riffle shuffles with stopping time $k$.
Now we're in great shape. If $T$ is the stopping time of a sequence of inverse riffle shuffles, we may apply our earlier result:
\[ \|R^k-U\| = \|\overline{R}^k - U\| \leq P(T> k).\]
We'll compute $P(T>k)$, the probability that the stopping time is greater than $k$, by working instead with $P(T\leq k) = 1 - P(T>k)$. Suppose we have a sequence of $k$ inverse riffle shuffles with $T\leq k$ (if $T< k$, just shuffle a few more times for a total of $k$ shuffles). As before, this leads to an ordering $\pi$ and a set of $n$ distinct $k$-bit strings. The number of orderings $\pi$ is $n!$ and the number of $n$ ordered distinct $k$-bit strings is $n!{2^k\choose n}$ since there are $2^k$ $k$-bit strings. This means that the number of sequences of $k$ inverse riffle shuffles with a stopping time less than $k$ is
\[(n!)^2{2^k\choose n}.\]
Now the total number of sequences of $k$ inverse riffle shuffles is the number of orderings $\pi$ times the number of length $n$ $k$-bit strings, which is $n!(2^k)^n$. This gives:
\begin{align} P(T\leq k) & = \frac{(n!)^2{2^k\choose n}}{n!(2^k)^n} \\ & = \frac{2^k!}{(2^k-n)!(2^k)^n} \\ & = \prod_{j=1}^{n-1}\left(1-\frac{j}{2^k}\right). \end{align}
This leads to the estimate
\[ \|R^k - U\| \leq P(T>k) = 1 - \prod_{j=1}^{n-1}\left(1-\frac{j}{2^k}\right).\]
With this in hand, let's consider shuffling a typical deck of $n=52$ cards using riffle shuffles. We find the following bounds on the distance of $R^k$ and $U$, which we will denote by $d(k)$:
| $k$ |
$d(k)$ |
| 1 |
1.00 |
| 2 |
1.00 |
| 3 |
1.00 |
| 4 |
1.00 |
| 5 |
1.00 |
| 6 |
1.00 |
| 7 |
1.00 |
| 8 |
1.00 |
| 9 |
0.93 |
| 10 |
0.73 |
| 11 |
0.48 |
| 12 |
0.28 |
| 13 |
0.15 |
| 14 |
0.08 |
| 15 |
0.04 |
| 16 |
0.02 |
| 17 |
0.01 |
| 18 |
0.01 |
| 19 |
0.00 |
|
 |
With this as our guide, we see that $d(k)$ is relatively constant for small $k$ but decreases exponentially for larger $k$. There is consequentially a region of transition where $d(k)$ changes from roughly constant to decaying exponentially. It seems reasonable that some value $k$ in the middle of this transition gives an appropriate number of shuffles to guarantee that the deck is sufficiently randomized. Using this model, it appears that $k=12$ would be a good recommendation for the number of shuffles.
Summary
A more sophisticated study enabled Diaconis and Bayer to improve this bound: for a deck of $n=52$ cards, they found
| $k$ |
$d(k)$ |
| 1 |
1.00 |
| 2 |
1.00 |
| 3 |
1.00 |
| 4 |
1.00 |
| 5 |
0.92 |
| 6 |
0.61 |
| 7 |
0.33 |
| 8 |
0.17 |
| 9 |
0.09 |
| 10 |
0.04 |
|
 |
Based on this analysis, Diaconis has written that "seven shuffles are necessary and suffice to approximately randomize 52 cards." Of course, our technique has just given an upper bound for the distance between $R^k$ and $U$. In fact, J. Reeds, in an unpublished manuscript, introduced a technique to find a lower bound: $\|R^6 - U\| \geq 0.1$. This lends further evidence to the fact that seven shuffles should be used. Please see the Postscript to this article for a further discussion. .
Of course, we could use a computer to generate random orderings of the deck, but we still need a reliable method to ask the computer for the next ordering. Bridge Clubs originally swapped 60 cards at random, but Diaconis and Shahshahani showed that this is not enough to generate sufficiently random orderings.
Knuth describes a process that proceeds in stages beginning at $i = 1$. Choose a random number $j$ so that $i\leq j\leq n$ and interchange the cards at positions $i$ and $j$. This generates the uniform probability density with 51 swaps.
A description of the current process using by Bridge Clubs is given by the website Bridge Hands.
Does it really matter? Yes! Martin Gardner describes some card tricks that rely on the fact that three riffle shuffles is not enough to generate random orderings. For example, suppose that a deck is shuffled three times and cut in between the shuffles. If a card is taken out, recorded, and put back in the deck in a different position, then that card can be determined almost all the time. De Bruijn also describes a similar trick.
The model we have adopted for the riffle shuffle seems reasonable, but how well does it model shuffles performed by a human? It depends on the human. Studies show that professional dealers drop single cards from one hand roughly 80% of the time and pairs about 18% of the time. Less experienced shufflers drop single cards about 60% of the time. Of course, when you're playing Crazy Eights with a kid, the cards sometimes get thrown all over the room resulting in the uniform distribution after one toss!
Postscript
Since this article was first published, several readers have contacted me regarding Diaconis' claim that seven riffle shuffles are sufficient to randomize a deck of 52 cards. A good summary of these readers' comments is contained in the end notes of Chapter 8 of the text Markov Chains and Mixing Times by David Levin, Yuval Peres, and Elizabeth Wilmer, published by the American Mathematical Society and available at http://pages.uoregon.edu/dlevin/MARKOV/:
Is it in fact true that seven shuffles suffice to adequately randomize a 52-card deck? ... After seven shuffles, the total variation distance from stationarity is approximately 0.3341. That is, after 7 riffle shuffles the probability of a given event can differ by as much as 0.3341 from its value under the uniform distribution. Indeed, Peter Doyle has described a simple solitaire game for which the probability of winning when playing with a uniform random deck is exactly 1/2, but whose probability of winning with a deck that has been GSR [riffle] shuffled 7 times times from its standard order is 0.801 (as computed in van Zylen and Schalekamp (2004)).
Ultimately the question of how many shuffles suffice for a 52-card deck is one of opinion, not mathematical fact. However, there exists at least one game playable by human beings for which 7 shuffles clearly do not suffice. A more reasonable level of total variation distance might be around 1 percent, comparable to the house advantage in casino games. This threshold would suggest 11 or 12 as an appropriate number of shuffles.
References
- David Aldous and Persi Diaconis, Shuffling cards and stopping times, American Mathematical Monthly 93, 1986, 333-48. Also available at http://www.jstor.org/pss/2323590.
- Martin Aigner and Günther Ziegler, Proofs from THE BOOK, Third Edition, Springer-Verlag, 2003
- Persi Diaconis, Mathematical developments from the analysis of riffle shuffling, in "Groups, Combinatorics and Geometry" edited by Ivanov, Liebeck, and Saxl. World Scientific, 2003, 73-97.
- Dave Bayer and Persi Diaconis, Trailing the Dovetail Shuffle to its lair, Annals of Probability 2, 1992, 294-313. Also available at http://projecteuclid.org/DPubS?service=UI&version=1.0&verb=Display&handle=euclid.aoap/1177005705.
- Martin Gardner, Scientific American, August 1960.
- Persi Diaconis and Mehrdad Shahshahani, Generating a random permutation with random transpositions, Probability Theory and Related Fields 57, 159-79. Also available at http://www.springerlink.com/content/j602u8m7w061467r/.
- Donald Knuth, The Art of Computer Programming, Volume 2: Seminumerical Algorithms, 3rd edition, Addison-Wesley, 1998.
- N.G. de Bruijn, A Riffle Shuffle Card Trick and its Relation to Quasicrystal Theory, Nieuw Archief Wiskunde 4, 1987, 285-301. Available at http://alexandria.tue.nl/repository/freearticles/597580.pdf.