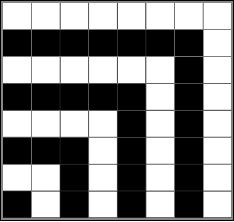
Periods
After a brief introduction to the combinatorics on words, which builds on some of the same ground that was discussed in a prior note, I will look at a remarkable theorem due to the mathematicians Herbert Wilf and Nathan Jacob Fine...
 Joseph Malkevitch
Joseph Malkevitch
York College (CUNY)
Email Joseph Malkevitch
Introduction
Mathematics is sometimes described as the science of studying patterns. Some mathematical patterns seem a bit hidden at first: 1, 1+3, 1+3+5, 1+3+5+7,.... The "rule" here seems clear enough; look at the sequence of adding the first n odd numbers. But there is a surprise! After the additions are carried out we see: 1, 4, 9, 16, .... The sum of the first n odd integers seems to be n times n, or n2. And since the alternately shaded white and black "hooks" in the diagram below (the case of n = 8) have an odd number of cells 1, 3, 5, etc. that fit together to form a square:
we see a way to realize that we have a pattern which can be described by the:
Theorem: The sum of the first n odd integers is n2.
Sometimes the pattern one might notice is related to repetition:
abcdabcdabcd
Here the pattern is that the block of letters abcd is repeated 3 times.
Whenever mathematicians get started on a problem by searching for patterns, whether it originates outside of mathematics (what stretches of DNA might be genes?) or for internal interests (how many palindromes, strings which read the same forwards or backwards, are there using an alphabet of m letters, with length k?), eventually it leads to new ideas and new mathematics. This growth of mathematics (and then in turn its applications) occurs by the process of generalization, abstraction, and working with analogies.
Patterns of repeats
In a prior column I looked at some topics in the combinatorics of words. Combinatorics on words studies properties and patterns present in strings of symbols like:
010201020102.... or abaabbaaabbbaaaabbbb....
whether they are finite strings of symbols or infinite strings of symbols.
In particular, that column discusses the Thue-Morse Sequence, a sequence in an alphabet with 2 letters with many remarkable properties, including the fact that it contains no "cubes" or "near-cubes." Another example of an infinite word with remarkable properties was studied by William Kolakoski and is known as the Kolakoski sequence.
Here is the sequence:
12211212212211211221211212211....
How was this sequence formed? This sequence uses an alphabet of two symbols, 1 and 2. Look at the runs, the number of repeats of each letter in the sequence. Count the lengths of the runs: one 1, two 2's, two 1's, one 2, one 1, two 2's, etc.
If we write down the lengths of these runs we get 122112.... which is exactly the sequence above! It can be shown that the only other sequence of 1's and 2's with this property is:
2211212212211211221211212211....
which is the sequence of symbols above but with the initial 1 deleted.
As an example of the kinds of simple questions that defy finding answers in looking at the sequence one might want to know what "relative frequency" the 1's in the sequence have. In the first 12 terms there are 5 ones or .4166.... of the total elements in the string. By the time 20 terms are reached there are 10 ones and 10 twos, that is, .5 of them are ones. Does the fraction of 1's get closer and closer to a particular fraction and is that fraction 1/2? Remarkably, no one knows!
Just as the Thue-Morse sequence has remarkable properties there have been other sequences constructed which are remarkable for the strings they "avoid." Thus:
Theorem (Aviezri Fraenkel and Jamie Simpson (1995))
One can construct an infinite word using 0's and 1's containing only three squares (words of the form u2), two cubes (words of the form u3), and no other repeats of powers ≥ 2.
In the word context, the notion of a repeated symbol or group of symbols, such as xx or xyzxyzxyz = (xyz)3 seems a very natural pattern to look for or to notice. What would the analogue of this be in the case of a variable which was continuous rather than discrete? What we see here is a pattern repeated over again a certain number of times. This is the idea of periodicity, something that repeats regularly over and over again. Here, for example, is a diagram showing something that is repeated over and over again in the continuous environment, though we only see a finite number of repetitions--the pattern is cut off on both sides.
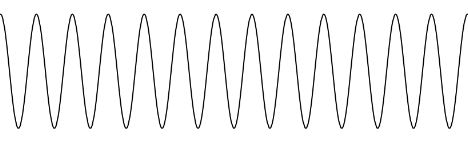
This is a graph of the trigonometric function y = sin(x). You see that one can think of the graph above as a shape that gets repeated over and over again many times, just as (xy)4 can be thought of as xy multiplied by itself four times.
In addition to the sine "wave" the diagram below shows other repeated or periodic graphs. The period of such a graph is the amount one has to move along the horizontal axes for the pattern to repeat. To those familiar with the "technical" definition of function, the second and fourth examples are not functions, though the graphs repeat at a fixed interval.

Periodic graphs (Courtesy of Wikipedia)
In the examples above we can find a "fundamental region" which gets repeated over and over again which leads to the idea that the pattern one is seeing is periodic--i.e. happens regularly in space.
People interested in fabric design and art are also interested in periodic patterns. Here are two such patterns:
Border or frieze patterns (Courtesy of Wikipedia)
Rather surprisingly, if one considers the "content" variety of frieze patterns there are only 7 such patterns of a single color design on a background with a different color.
Patterns of this kind are periodic in one space dimension. One can also have periodic patterns in two dimensions. These are sometimes referred to as wallpaper designs. Using one color on a background which is a different color there are exactly 17 such groups. Recently, using ideas of William Thurston, John Conway has developed a notation and approach to these 17 patterns which explains why there are 17 in a more natural way than the ad hoc arguments of the past had accomplished.
After a brief introduction to the combinatorics on words, which builds on some of the same ground that was discussed in a prior note, I will look at a remarkable theorem due to the mathematicians Herbert Wilf and Nathan Jacob Fine. While this result was not specifically discovered in the context of the emerging body of work on combinatorics on words, it is a remarkable example of how mathematics operates--important ideas in one domain are studied and generalized in other domains, often to the mutual benefit of both domains and also offering ideas for applications.

Herbert Wilf (Photo courtesy of Wikipedia)

Nathan Jacob Fine (1916-1994) (Photo Courtesy of Wikipedia)
Nathan Jacob Fine (1916-1994) spent his career at Pennsylvania State University but got his doctorate degree from Antoni Zygmund at the University of Pennsylvania in 1946. As an aside, the mathematics building at Princeton University is called Fine Hall, and mathematicians may be tempted to think it is named for Nathan Fine. In fact, Fine Hall is named for Henry Burchard Fine (1858-1928) a dean at Princeton who did much to make Princeton a center for research in mathematics.
The intuition about a period for functions that go off to infinity in both directions is that one can shift the diagram along the x-axis (translate the diagram) and the graph will superimpose on itself. There may be many amounts one can translate by and get a superposition effect. One thinks of the period as the minimal amount that one can translate by and accomplish this.
However, what happens when one has a word, a string which is finite instead of infinite?
Comments?
Combinatorics on words
The area of mathematics known as combinatorics on words has exploded in recent years with a large volume of new results. There have been many attempts to summarize and understand what has been done in the past but they are scattered throughout different parts of the mathematical literature. As is often true in rapidly emerging fields there are often concepts that are defined slightly differently (using different terms for the same idea) or the same term is used to mean not exactly the same thing. Happily, there is a growing consensus about how to organize these ideas so that one can see what the field is accomplishing. However, for better or worse, there is a fair amount of "technical" vocabulary. Here I will try to "conversationally" define the important terms that encompass the ideas involved but will, wherever possible, work using examples, rather than giving a very formal approach.
A string is sequence of symbols drawn from an alphabet. Strings can be infinite in two directions:
......abcabc......
...12111098765432101234567891011....
or infinite in only one direction:
aabbccaabbccaabbcc....
....aaaaaabbbaabbbb
or finite:
101100111000111000
12121212121212121
The first and third strings use an alphabet of three symbols, the second is drawn from the alphabet of decimal digits (0, 1, 2, 4, 5, 6, 7, 8, 9). The remaining strings use two-letter alphabets.
Given a word over an alphabet we can create new words by concatenating other words and we can "factor" a word into smaller pieces.
To help understand the basic ideas consider the word w:
w = aabaabaabaa (*)
We have that aabaab is a subword or factor this word. This factor appears in two different places, once starting in position 1 of word w and the other time starting in position 4 of w. The first appearance of aabaab, starting in position 1 is also referred to as a prefix of w. Other prefixes of w are aa, aab, aabaabaab. One also has, analogously to the idea of a prefix, the notion of a suffix. Thus, we have aa as a suffix of w, as well as aabaa as another suffix. Sometimes factors can be both suffixes and prefixes of a word. For example w has aa as both a suffix and prefix and also aabaa as both a suffix and prefix.
When a finite string is not the power of a smaller string repeated over and over again, we still might notice that there is a pattern of parts of this string that repeat several times. There are different intuitive ways that one can get this notion across. For example, consider the string:
aabaabaaba
Now let us move this string one unit to the right and look at how the two strings "line up," "match," or "align."
aabaabaaba-
-aabaabaaba
Although we have yet to offer a formal definition, these two don't seem to line up very well, with only occasional matches between the two strings.
Given two strings X and Y, even if they are not the same length, one can try to see how they are "related." Below are two strings X and Y of different lengths from the DNA alphabet, A,C, G, and T. We can construct a binary string which gives information about how the two strings "match." This can be done by lining up the strings starting at the left (left-adjusted). We record if Y matches X in all of the positions they overlap in by recording a 1 for such an overlap match and a 0 for no such match. Then we shift the string Y one position to the right and check for a match in all overlapping positions in the shifted position. We can repeat this process over and over until we exhaust the "columns" of X. Shown below is this process carried out for two particular strings X nd Y.
X = TGCAGCA
Y = GCAGCATT
GCAGCATT
GCAGCATT
GCAGCATT
GCAGCATT
GCAGCATT
GCAGCATT
We see that we get 0, 1, 0, 0 1, 0, 0 as the pattern using the "code" described above.
These ideas are related to the concept of how far two strings are apart--distance between strings. When strings have the same length one can use Hamming Distance and when they are unequal in size one can use edit distance or Levenshtein Distance. The computation above involves what is called the correlation of the sequences (words) X and Y. In general, the correlation of X and Y will not be the same as the correlation of Y and X, even for strings of the same length. Furthermore, one can compute the correlation of X and itself. This is known as the autocorrelation of a word or string.
Comments?
Period patterns for words
Some issues of the period of a string involve the idea of a greatest common divisor of two integers. Remember that here we are looking at strings that might use digits as their alphabet. However, every string has a length which is a number and for the notion of a period we are concerned in part with the issue of lengths of strings and of substrings of a given string.
What is a natural way to say that a finite word has some "period?" Intuitively the idea would be that some subword of the word gets repeated through part of the word but towards the "end" of the word there may be part of this "repetition" that is not "complete."
Suppose x is a word (string). Then we will denote the length of x by |x|. We will use x[i] to denote the element of x in the i th position of x.
Consider for example the word:
w = aabaaabaa
Note that the string aabaaabaa and 001000100 are the "same" from a string point of view--they use a two-letter alphabet and have the corresponding symbols in the same positions. To avoid confusion between numbers and strings we will usually use letter alphabets rather than those with digits.
Above we have that |w| = 9 and w(3) = b, w(4) = a, w(8) = a. If we shift this word a certain number of characters to the right, then the letters in the corresponding positions may be identical. When this happens it seems "reasonable" to call this a period of the string.
Here is the formal definition:
p is a period of string x if p is an integer, 0 < p ≤ |x|, and x(i) = x(i+p) for i = 1, 2, ...., |x| - p.
A string can have many periods, and we will agree that it always has as a period p, the value of its length. It is customary to say that period(x) is the smallest (shortest) of x's possible periods. It is also customary to call a string x periodic if period(x) is less than or equal to |x|/2.
Example 1:
Given our string:
w = aabaaabaa
what periods does it have?
Let's first see why 1 is not a period of w. Since 9 - 1 = 8 we have tomake checks for values of i from 1 to 8. We have to check (i = 1) if w(1) is equal to w(1 + 1) = w(2). Since w(2) = a and w(1) = a, so far so good. Now we have to use i = 2, and check if w(2) = w(2 + 1) = w(3). Since w(2) = a but w(3) = b, we conclude that 1 is not a period of w.
The number 2 is also not a period of w because w(1) = a is not equal to w(1 + 2) = w(3) = b. Thus, w(1) is not equal to w(3) as would be required for 2 to be a period.
The number 3 is not a period of w but what about 4? Note the length of x - 4 is 5, so if 4 is a period we need to check cases where i can take on the values 1 to 5. Since we have w(1) = a = w(5), w(2) = a = w(6) =a, w(3) = b = w(7), w(4) = a = w(8) and finally, w(5) = w(9) = a. Thus, 4 is a period of this word.
Note that the shorter the possible period, the larger the number of checks that are required to see if it truly is a period. We can check that 5 and 6 are not periods of w.
We can see that 7 is also a period of w. To check this, since 9 (the length of w) -7 = 2 we have to check that two positions (8 and 9), w(8) and w(9) line up with w(1) and w(2). Thus, since w(1) = w(8) = a and w(2) = w((9) =a, we conclude 7 is a period of w. You can also check that 8 is a period of w.
What about 9? Is 9 a period of w? It is convenient to have the length of a word always be a period of the word, so, in fact, every word that has length at least 1 has its length as a period. (Since |w| = 9 and 9 - 9 = 0, we have no "checks" to make, so 9 is a period, automatically as it were).
For this string w, we have that w has periods of length 4, 7, 8, and 9. Thus, we can say that period(w) = 4, and since 4 < 9/2, we would call this word periodic.
As previously explained, x(i) denotes the letter of the string in the i-th position of the string. For those familiar with "function" notation, we can think of what is happening here as defining a function on a string and x(i) picks out the i-th letter of the string as its "output" given the input string x.
Without the details here are a few more examples so that you can check, if you would like, that you understand the definitions given:
Example 2:
y = abracadabra
y has length 11.
The string y has periods 7, 10 and 11.
Example 3:
z = blablablablablablabl
z has length 20.
The periods of z are 3, 6, 9, 12, 15, 18, and 20.
The pattern one notices here is that there are repeats of "bla" but there is a "trailing" bl at the end.
Many natural mathematical and computer science questions arise from this circle of ideas. First of all, given a word x based on an alphabet with k letters and having length n, how hard is it to:
a. Determine a period of word x other than the period n? (The length of a word is a period of any word.)
b. Determine all of the periods of word x.
c. Given a set of integers, when can one construct a word x with these periods using an alphabet of k letters, and when there is such a word with the required periods using k letters, what is the shortest length it can have?
Furthermore, if a string has been determined to have certain periods, can one conclude that it must have other periods? This issue is the genesis of the Fine-Wilf Theorem. Over the years Fine-Wilf has been looked at from many perspectives and extended in various directions. Here I am interested in its statement for finite words, that is, in the context of the kinds of examples we have just looked at. I will give two versions of the theorem though sometimes one is used as a lemma for the other. Before stating the theorem, here is a reminder about the concept of the greatest common divisor of two positive integers and some interesting mathematics related to this concept.
The greatest common divisor of two positive integers u and v is the largest integer d which divides both u and v. We will use the abbreviation gcd for greatest common divisor. Often in school, the way one is taught to compute the greatest common divisor of two integers u and v by constructing the prime factorization of u and v and picking out as the gcd, the higher power of each prime that appears in both, and multiplying these together:
Example:
Find the greatest common divisor of 56 and 64.
56 = 23(7)
64 = 26
The only prime repeated in both is 2. The highest power that appears in both numbers is 3 so the gcd of 56 and 64 is 8.
However, not as widely known as it should be, Euclid, yes, the same chap for whom Euclidean geometry is named, found a much more elegant approach to the gcd. Euclid realized that given two different positive integers, if we divide the smaller into the larger and find the remainder of this division, that the gcd of the remainder and the divisor used are the same as that for the original two numbers. So rather than factoring two numbers and doing some extraction of powers of primes, we can use integer division over and over to find a gcd. For the example above, 64 = 1(56) + 8. Thus, the gcd of 56 and 64 is the same as the gcd of 8 and 56. It is now apparent that the gcd of 56 and 64 is 8.
If one uses the approach of Euclid to find a gcd, namely applying division over and over again, it turns out that the gcd of two numbers is the last non-zero remainder in carrying out the string of divisions.
Example:
Find the gcd of 1000 and 2440.
Using successive divisions we get:
2440 = 2(1000) + 440
1000 = 2(440) + 120
440 = 3(120) + 80
120 = 1(80) + 40
80 = 2(40) + 0
Thus, the gcd of 1000 and 2440 is 40, the last non-zero remainder we got.
The usual approach to this problem would have required that one determine that:
1000 = 2353
and that
2440 = 23(5)(61)
from which one also sees that the answer is 40.
A fringe benefit of applying the Euclidean Algorithm is that it gives a method of solving integer diophantine equations, equations where one is interested in finding integer solutions. Thus, to solve:
ax + by = c
where a, b, and c are fixed integers, one can use ideas related to the Euclidean Algorithm. In the case above, can you see how to find x and y so
440x + 1000y = 40?
(Hint: Work backwards using the equations in the gcd calculation above:
40 = 1(120) - 1(80)
40 = 1(120) - 1(1(440) - 3(120)) = 4(120) -1(440)
40 = 4(1(1000) - 2(440)) -1(440) = 4(1000) -9(440)
Theorem (Nathan Fine and Herbert Wilf):
a. If p and q are distinct periods of a word x and p + q is smaller than the length of x (i.e. p + q < |x|) then the greatest common divisor of p and q is also a period of x.
b. If p and q are distinct periods of a word x and p + q - gcd (p,q) is smaller than or equal to the length of x (i.e. p + q - gcd (p, q)) ≤ |x|) then the greatest common divisor of p and q is also a period of x.
To help understand the Fine-Wilf result consider the following example, which both illustrates the theorem and helps supplement the examples discussed prior to the theorem.
Example 4:
S = aabaabaabaabaabaabaabaab
The length of S is 24, that is |S| = 24.
a. 9 is a period of this string
b. 6 is a period of this string
Since 9 + 6 = 15 is less than 24, we can conclude that 3, which is the greatest common divisor of 6 and 9, is also a period of S.
Comments?
Borders and periods
The phenomenon that there may be subwords of a word that are both prefixes and suffixes leads to what for me was an unexpected phenomenon, namely the idea captured using the term "border." A border of a word is a subword which is both a prefix and a suffix of the word. It came as a surprise to me that the concept of a border is related to the issue of a period. If a subword u of a string is a prefix and a suffix, and if we shift the string with prefix u to the start of where u appears as a suffix, all of the letters will line up. Thus, such a shift by the length of u will be a period of our string.
In the theory of sets, collections of objects, it is convenient to have a set which has no elements, namely the null set. Similarly, in many cases it is convenient to have a special symbol for the word with no letters, the empty word. Traditionally, the empty word is denoted with the Greek letter epsilon. It is also convenient to think of a word as being a factor of itself. So with this in mind we can view the word w in (*) above as both a suffix and prefix of itself. The diagram below shows a word x which has a suffix (top) and a prefix (bottom) which are the same and are labeled border--a border on the right at the top, and a border on the left at the bottom. So if we shift the string from its start to the beginning of its suffix, the string will fall on top of itself (shown in separate lines below). Thus, we can go back and forth between the idea of a border and finding a period of the string x.

Given a string x, let border(x) denote the longest border of x that is not the whole word itself. We see that |x| - border(x) is the amount we must shift x to the right for the start of x to be located at the start of the suffix copy of the border. (Look at the diagram above.) If we compute the "border function" of border(x) we can locate another period of x. We can do this over and over again until we get all of the periods of x.
To help you cement the relation between borders and strings consider the following example:
Example:
Z = blablablablablablabl
Here is a list of the strings (other than the null string and z itself) that occur as borders (simultaneously prefixes and suffixes) in Z, which has length 20 (|Z| = 20):
bl
blabl
blablabl
blablablabl
blablablablabl
blablablablablabl
How can we use these strings to find the periods of a string z?
The border of length 2 means a period of length 18, the border of length 5 means a period of length 15, ...., border of 17 means a period of length 3.
So the set of periods here are {3, 6, 9, 12, 15, 18, 20} where the period of length 20 for the whole word has be included. Note that the Fine-Wilf theorem means that knowing that 9 and 12 are periods, and that the gcd of 9 and 12 is 3, then 9 + 12 - 3 = 18 is also a period.
The string aabaaba and 0010010 are the "same" from a string point of view--they use a two-letter alphabet and have the corresponding symbols in the same positions. How does the number of symbols in an alphabet relate to the periods that words can have in that alphabet?
Again, it seems remarkable to me that this question can be completely answered by a theorem of Leonidas Guibas and Andrew Odlyzko that dates to 1981, some years after the Fine-Wilf Theorem was proven.


Photos of Leonidas Guibas and Andrew Odlyzko (Courtesy of Wikipedia and Professor Odlyzko)
Given a set of integers, Guibas and Odlyzko determined whether that set of integers can be the periods of a word. They also showed that if x is a word using an alphabet with k letters (k > 2) with P being the set of its periods, then there is a word x* of the same length as x which uses 0 and 1 as its alphabet (e.g. a binary alphabet) which has the same set P for its periods as x.
Example:
abaacabaacaba (13 letters)
has periods of 5, 10, 12, 13 (including the whole word)
and the word in two letters:
abaaaabaaaaba (13 letters)
also has periods 5, 10, 12, 13 (including the whole word).
Note that though 10 and 12 have gcd equal to 2, 2 is not a period of these words. This does not violate the Fine-Wilf theorem because, 10 + 12 - 2 is not less than or equal to 13, the length of our string.
Patterns are all around us--and they are at the core of what mathematics is about. And then, clever people find ways to put this mathematics to use for mankind.
Comments?
Bibliography
Allouche, J-P. and J. Shallit, The ubiquitous prouhet-thue-morse sequence, in Sequences and their applications, pp. 1-16. Springer, London, 1999.
Allouche, J-P. and J. Shallit. Sums of digits, overlaps, and palindromes, Discrete Mathematics & Theoretical Computer Science 4 (2000) 1-10.
Allouche, J.-P. and J. Shallit, Automatic Sequences: Theory,
Applications, Generalizations, Cambridge U. Press, New York, 2003.
Berstel, J., Axel Thue’s work on repetitions in words, Séries formelles et combinatoire algébrique 11 (1992) 65-80.
Berstel, J. and L. Boasson, Partial words and a theorem of Fine and Wilf, Theoret. Comput. Sci. 218 (1999) 135–141.
Berstel, J. and J. Karhumäki, Combinatorics on words: A tutorial, Bull. Eur. Assoc. Theor. Comput. Sci., EATCS 79 (2003) 178–228.
Berstel, J., Axel Thue's work on repetitions in words. In P. Leroux, C. Reutenauer (Eds.) Séries Formelles et Combinatoire Algébrique (Number 11 in Publications du LACIM, Université du Québec â Montréal, 1992 ), pp 65–80.
Berstel, J. and D. Perrin, The origins of combinatorics on words, European Journal of Combinatorics 28 (2007) 996-1022.
Chao, K-M. and L. Zhang, Sequence Comparison, Springer, New York, 2009.
Crochemore, M., Sharp characterizations of squarefree morphisms, Theoret. Comput. Sci. 18 (1982) 221–226.
Crochemore, M. and D. Perrin, Two-way string matching, J. ACM 38 (1991) 651–675.
Crochemore, M. and W. Rytter, Jewels of Stringology, World Scientific, 2002.
Crochemore, M. and W. Rytter, Text Algorithms, Oxford University Press, 1994.
Crochmore, M. and C. Hancart, T. Lecroq, Algorithms on Strings, Cambridge U. Press, 2007.
Czumaj, A. and G. Leszek Gçasieniec. On the complexity of determining the period of a string, in Combinatorial Pattern Matching, Springer, Berlin Heidelberg, 2000, p. 412-422.
Farach-Colton, M., (ed.), Combinatorial Pattern Matching, Lecture Notes in Computer Science, Volume 1448, Springer, New York, 1998.
Fine, N. and H. Wilf, Uniqueness theorems for periodic functions, Proc. Amer. Math. Soc. 16 (1965) 109–114.
Fraenkel, A. and J. Simpson, How many squares can a string contain?, Journal of Combinatorial Theory, Series A, 82 (1998) 112-120.
Fraenkel, A. and J. Simpson, An extension of the periodicity lemma to longer periods, Lecture notes in computer science, Springer, 2001, p. 98-105.
Fraenkel, A. and J. Simpson, An extension of the periodicity lemma to longer periods, Discrete Applied Mathematics, 146 (2005) 146 – 155.
Guibas, L. and A. Odlyzko, Long repetitive patterns in random sequences, Zeitschrift für Wahrscheinlichkeitstheorie und verwandte, 53 (1980) 241-262.
Guibas, L. and A Odlyzko, Periods in strings, Journal of Combinatorial Theory, Series A 30 (1981) 19-42.
Guibas, L and A. Odlyzko, String overlaps, pattern matching, and nontransitive games, Journal of Combinatorial Theory, Series A 30 (1981) 183-208.
Gusfield, D., Algorithms on Strings, Trees, and Sequences, Cambridge U. Press, New York, 1997.
Lothaire, M., Combinatorics on Words, Addison-Wesley, 1983.
Lothaire, M., Algebraic Combinatorics on Words, Cambridge University Press, New York, 2002.
Lothaire, M., Applied Combinatorics on Words, Cambridge U. Press, New York, 2005.
Louck, J., Problems in combinatorics on words originating from discrete systems, Ann. Comb., 1 (1997) 99–104.
Morse, M., Recurrent geodesics on a surface of negative curvature, Trans. Am. Math. Soc. 22 (1921) 84–100.
M. Morse, A solution of the problem of infinite play in chess, Bull. Am. Math. Soc., 44 (1938) 632.
M. Morse and G. Hedlund, Symbolic dynamics, Am. J. Math. 60, (1938) 815–866.
Nagell, T., and A. Selberg, S. Selberg, K. Thalberg. Selected mathematical papers of Axel Thue. Universitetsforlaget, Oslo, 1977.
Navarro, G. and M Raffinot, Flexible Pattern Matching in Strings, Cambridge U. Press, New York, 2002.
Offner, C., Repetitions of words and the Thue-Morse sequence. (Preprint)
Palacios-Huerta, I., Tournaments, fairness and the prouhet-thue-morse sequence, Economic inquiry 50 (2012) 848-849.
Séébold, P ., On some generalizations of the Thue–Morse morphism, Theoretical computer science 292, (2003) 283-298.
Shallit, J., A Second Course in Formal Languages and Automata Theory, Vol. 179. Cambridge: Cambridge University Press, New York, 2009.
Thue, A., Uber unendliche Zeichenreihen, Kra. Vidensk. Selsk. Skrifter. I. Mat.-Nat. Kl., Christiana, Nr. 7, 1906.
Thue, A., Uber die gegenseitige Lage gleicher Teile gewisser Zeichenreihen, Kra. Vidensk. Selsk. Skrifter. I. Mat.-Nat. Kl., Christiana, Nr. 12, 1912.
Williamson, Christopher, An overview of the Thue-Morse sequence. (Unpublished manuscript.)
Note: Jeffrey Shallit maintains a Wiki where those interested in the combinatorics on words can interact and post information about combinatorics on words problems and ideas. Springer has published several volumes on combinatorial pattern matching in its Lecture Notes in Computer Science series.
Those who can access JSTOR can find some of the papers mentioned above there. For those with access, the American Mathematical Society's MathSciNet can be used to get additional bibliographic information and reviews of some these materials. Some of the items above can be found via the ACM Portal, which also provides bibliographic services.
Joseph Malkevitch
York College (CUNY)
Email Joseph Malkevitch