Digital Revolution (Part III) - Error Correction Codes
2. Basic ideas
The idea behind an error correcting code is surprisingly simple. Suppose one has codewords consisting of zeros and ones which all have the same length. Let us define the distance between two codewords to be the number of places the code words differ.
For example, if one has two codewords of length 11, as is the case for the two binary strings below
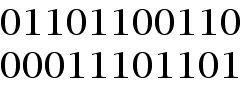
the distance between these two code words would be 6 because the strings differ in 6 columns (e.g. columns 2, 3, 4, 8, 10, and 11). We are using the word distance here, because the concept which has just been defined obeys all the same properties that Euclidean distance obeys. Today, this kind of distance is called Hamming distance in honor of Richard Hamming. Hamming distance is an important concept not only for computing the distance between strings of binary digits, but for strings taken from other "alphabets" as well. In particular, Hamming distance has been put to use in molecular genetics.
The brilliant insight that Hamming had was that if one has a collection of codewords, each pair of which are at least 2e + 1 apart as measured by the Hamming distance, then one can correct up to e errors (per codeword). The reason is this. Suppose that a received string R differs from the string that was sent S in no more than e positions. Note that the only strings that are sent are codewords, while the received string may or may not be a codeword. Compute the distance between R and all the codewords. Since at most e errors occurred, the received string must lie within the "circle" centered around one of the code words with radius e.

The diagram above suggests what is going on. The dark dots are codewords. The circles of radius e around these dots are shown. As long as these circles are disjoint from each other, that is, do not overlap, a received string that has no more than d transmission errors lies within one of the circles and can be properly decoded. Of course, one can not know in advance how many errors might actually be made. In some very special cases all potential messages of the codeword length are included in the circles centered around the code words. When this happens, the code is known as perfect. Perfect codes are especially appealing and by 1975 a complete list of such codes was known. The number of errors that occurs is related to the "quality of the hardware" used in the given situation (a malfunction in the hardware might increase the number of errors) and the amount of noise. NASA might design a code for use by a spacecraft under normal solar conditions, but an unexpected solar flare might create a situation where many more errors would occur than might have been expected .
The other fundamental idea that Hamming (and others) realized was that one could add redundant symbols to the information one wanted to transmit, thereby achieving error correction capability. Suppose one is analyzing English text and one wants to code the pattern of consonants and vowels in the text. Each letter in the text is either a vowel or a consonant. Suppose a 1 represents a vowel and a 0 represents a consonant. For example, one would encode "mathematics" as: 01001010100. If errors occurred in the transmission of this binary string, there would be no way of knowing that the pattern did not represent a pattern of vowels and consonants. (In the case of eleven-letter words, one would know an error had been made if a received pattern did not correspond to any legal word. For shorter binary sequences this would not work.) To overcome this uncertainty, one could use 111 for a vowel and 000 for consonant. Now instead of using eleven symbols, one is using thirty-three. This use of redundancy not only takes up more space but would require more time transmitting a message.
The system above would enable the correction of up to one error per original information symbol because if, say, 001 were the first three symbols received, one would reason that the symbol consonant was meant because 001 differs from 000 in one position, while 001 differs from 111 in two positions. It seems more likely that one error occurred than two errors, so it is reasonable to conclude that the first letter of the text was a consonant. Two aspects of this system are noteworthy. One feature is that it is very easy to encode the message; just repeat each binary symbol three times. Secondly, it is also relatively easy to decode the message. Merely group the received string (assuming no digits are created or dropped) and decode triples with more zeros than ones to 000 and triples with more ones than zeros to 111. Questions about transmission rates versus noise and the correction of errors lay at the heart of what Shannon was trying to understand.
Hamming realized that what he wanted to achieve was to add as few extra symbols as possible to each "information" string so as to get a code word that was relatively short but which still had the right level of error correction power (i.e. the ability to correct up to, say, d errors). However, he also understood that if it was very time consuming to either encode the original string or decode the received string, the method would not be practical.
Amazingly, the ideas of Shannon (shown below), Hamming, and Marcel J. E. Golay (1902-1989) have given rise to a whole new subfield of mathematics known as coding theory.

Coding theory collected and synthesized a large variety of ideas that cut across many other branches of mathematics: algebra, geometry, combinatorics, and topology, to mention a few. The term coding theory has two connotations. First, it is concerned with the theory and application of error correcting codes. This involves a wide variety of ideas for the design of such codes as well as methods for encoding and decoding code words so that the codes can be part of practical technologies. Second, coding theory is concerned with information in general and with how it is possible to deal with information in a "noisy" environment. The tools of this part of coding theory often involve the use of probability theory and statistical techniques. Sometimes the term information theory is used to describe this part of coding theory, unless you belong to the school of people who think of coding theory as being a part of information theory.
-
Introduction
-
Basic ideas
-
The channel concept
-
Codes and geometry
-
Theory and practice of codes
-
Error correction technologies
-
References
