PDFLINK |
The Image Deblurring Problem: Matrices, Wavelets, and Multilevel Methods
Communicated by Notices Associate Editor Reza Malek-Madani

1. Introduction
After the launch of the Hubble Space Telescope in 1990, astronomers were gravely disappointed by the quality of the images as they began to arrive. Due to miscalibrated testing equipment, the telescope’s primary mirror had been ground to a shape that differed slightly from the one intended, resulting in the misdirection of incoming light as it moved through the optical system. The blurry images did little to justify the telescope’s $1.5 billion price tag 1. Three years later, space shuttle astronauts installed a specially designed corrective optical system that essentially fixed the problem and yielded spectacular images (See the image on this page. Hubble’s view of the M100 galaxy soon after launch is on the left and on the right is the view after corrective optics were installed in 1993). In the meantime, mathematicians devised several ways to convert the blurry images into high-quality images. The process of mathematical deblurring is the focus of this article.
Blurred images can be caused by many factors such as the movement of the imaging device or the target object, focus errors, or the presence of atmospheric turbulence 12. Indeed, the need for image deblurring goes beyond Hubble’s story. For instance, the image deblurring problem is encountered in many applications such as pattern recognition, computer vision, and machine intelligence. Moreover, image deblurring shares the same mathematical formulation as other imaging modalities. For instance, in many cases we have only limited opportunities to capture an image; this is particularly true of medical images, such as computerized tomography (CT), proton computed tomography (pCT), and magnetic resonance imaging (MRI), for which equipment and patient availability are scarce resources. In cases such as these, we need a way to extract meaningful information from noisy images that have been collected during the data acquisition process.
In this article, we will describe a mathematical model of how digital images become blurry as well as several mathematical issues that arise when we try to undo the blurring. While blurring may be effectively modeled by a linear process, we will see that deblurring is not as simple as inverting that linear process. Indeed, deblurring belongs to an important class of problems known as discrete ill-posed problems 10, and we will introduce some techniques that have become standard for solving them. In addition, we will describe some matrix structures in the linear operators that will allow more efficient computations.
2. Digital Images and Blurring
We start by describing digital images and a process by which they become blurry. As illustrated in Figure 1, the lens of a digital camera directs photons entering the camera onto a charge-coupled device (CCD), which consists of a rectangular array of detectors. Each detector in the CCD converts a count of the photons into an electrical signal that is digitized by an analog-to-digital converter (ADC). The result is a digital image stored as a matrix whose entries represent the intensities of light recorded by each of the CCD’s detectors.
A simple model of how a digital image is created.

A grayscale image is represented by a single matrix with integer entries describing the brightness at each location. A color image is represented by three matrices that describe the colors in terms of their red, green, and blue constituents. Of course, we may see these matrices by zooming in on a digital image until we see individual pixels, picture elements that contain only one intensity value.
Perhaps due to imperfections in the camera’s lens or the lens being improperly focused, it is inevitable that photons intended for one pixel bleed over into adjacent pixels, and this leads to blurring of the image. To illustrate, we will consider grayscale images comprised of arrays of pixels. In Figure 2, the image on the left shows a single pixel illuminated while on the right we see how photons intended for this single pixel have spilled over into adjacent pixels to create a blurred image.
The intensity from a single pixel, shown on the left, is spread out across adjacent pixels according to a Gaussian blur, as seen on the right.


There are several models used to describe blurring. A simple one that we choose here has the light intensity contained in a single pixel spilling over into an adjacent pixel according to the Gaussian point spread function
where is a parameter that controls the spread in the intensity and is a normalization constant so that the total intensity sums to 1. As we will see later, the fact that the two-dimensional Gaussian can be written as a product of one-dimensional Gaussians has important consequences for our ability to efficiently represent the blurring process as a linear operator.
Though we visually experience a grayscale image as a matrix of pixels , we will mathematically represent an image as a -dimensional vector by stacking the columns of on top of one another. That is, with being the intensity value of the pixel at row and column . The blurring process is linear as the number of photons that arrive at one pixel is the sum of the number of misdirected photons intended for nearby pixels. Therefore, if is the blurred image represented by the vector , then there is a blurring matrix that blurs the original image into the blurred image . Furthermore, we assume that both images and have the same size, as do and , which implies that the matrix is square. Deblurring refers to the inverse process of recovering the original image from its blurred counterpart and includes situations, unlike the one we describe here, where is not invertible or even square.
Each column of is the result of blurring a single pixel, which means that each column of represents the point spread function centered at its corresponding pixel . When that center is near the edge of the image, some photons will necessarily be lost outside the image, and there are a few options for how to incorporate this fact into our model. In real-life settings, it is possible to have knowledge only over a finite region, the so called Field of View (FOV), that defines the range that a user can see from an object. It is then necessary to make an assumption on what is outside the FOV by means of the boundary conditions. For instance, one option to overcome the loss outside the FOV is to simply accept that loss, in which case we say that the matrix has zero boundary conditions. This has the effect of assuming that the image is black (pixel values are zero) outside the FOV, which can lead to an artificial black border around a deblurred image (see the image on the left on Figure 3Footnote1).
We picked the letter H to celebrate Hispanic Heritage Month, which is the focus of this issue of Notices.
In some contexts, it can be advantageous to impose reflexive boundary conditions, which assume that the photons are reflected back onto the image. In other scenarios of interest, periodic boundary conditions, which assume the lost photons reappear on the opposite side of the image as if the image repeats itself indefinitely in all directions outside the FOV, are a suitable fit. Nevertheless, in practical settings, we periodically extend only some pixel values close to the boundary (see the image on the right on Figure 3).
Image with assumed zero boundary conditions is shown on the left and one with assumed periodic boundary condition is shown on the right. The red box represents the FOV.


3. Adding Noise
Let us consider the grayscale image shown on the left of Figure 4 and its blurred version shown on the right.
An image on the left is blurred to obtain on the right.


If we had access to , it would be easy enough to recover by simply solving the linear system since our model gives a square, invertible matrix . However, the conversion of photon counts into an electrical signal by the CCD and then a digital reading by the ADC introduces electrical noise into the image that is ultimately recorded. The recorded image is therefore a noisy approximation of the true blurred image , so we write , where is a noise vector whose entries are independent and identically distributed random variables. There are various models used to describe the kind of noise added. For instance, we might assume that the noise is Gaussian white noise, which means that the entries in are sampled from a normal distribution with mean zero. In our example, we assume that , that is, the white noise is about 0.1% of the image . As seen in Figure 5, this level of noise cannot be easily detected.
The blurred image on the left with a small amount of Gaussian white noise added to obtain on the right.

Two other models of noise are illustrated in Figure 6. The image on the left contains what is called Poisson noise. Under low light conditions, as encountered in astronomical imaging, the number of photons that arrive on the CCD are very low and therefore the noise produced is better modeled by a Poisson distribution than a Gaussian one 19. If the digital image is transmitted over a communication channel, some of the transmitted bits may be corrupted in transmission, resulting in “salt and pepper” noise, the effect of which is shown in the image to the right 12. This noise can be modeled by a uniform distribution whose standard deviation is inversely proportional to the number of bits used. In the rest of the article, we will assume that we have Gaussian white noise. Some references on how to model and solve other noise models are included in 20.
Poisson noise is added to the blurred image on the left and salt and pepper noise on the right.


Because our recorded image is a good approximation of , we might naïvely expect to find a good approximation of by solving the linear system of equations . However, its solution, which we call , turns out to be very different from the original image as is seen in Figure 7. As we will soon see, this behavior results from the fact that deblurring is a discrete linear ill-posed problem.
On the left we see the original image while the right shows , the solution to the equation , where is the noisy recorded image.

We are now faced with two questions: how can we reconstruct the original image more faithfully and how can we do it in a computationally efficient way. For instance, today’s typical phone photos have around 10 million pixels, which means that the number of entries in the blurring matrix is about 100 trillion. Working with a matrix of that size will require some careful thought.
4. Discrete Linear Ill-Posed Problems
The singular value decomposition (SVD) of the matrix offers insight into why the naïvely reconstructed image differs so greatly from the original . Consider both vectors and of dimension . Now suppose that has full rank and its SVD is given by
where and are matrices having orthonormal columns so that , and , with , that is to say, is an diagonal matrix, whose entries are positive and appear in decreasing order. The scalars are the singular values of and the vectors and are the left and right singular vectors of , respectively. In particular, the singular value decomposition provides orthonormal bases defined by the columns of and , for the range and domain spaces, respectively, so that . Notice that we are assuming that the matrix is square and full rank, since all the singular values are positive, and therefore invertible. This is natural in the image deblurring model described here. In other inverse problems, however, the matrix may be square but rank-deficient or even rectangular, situations whose solutions require more detailed considerations 10.
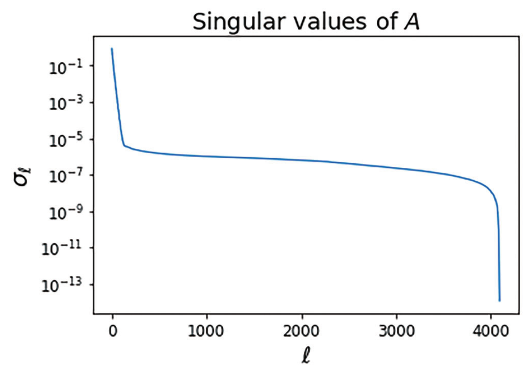
Discrete linear ill-posed problems are characterized by three properties, which are satisfied by the deblurring problem. First, the singular values decrease to zero without a large gap separating a group of large singular values from a group of smaller ones. The plot of the singular values in Figure 8 shows that the difference between the largest and smallest singular values is about thirteen orders of magnitude, which indicates that is highly ill-conditioned.
The singular values of .
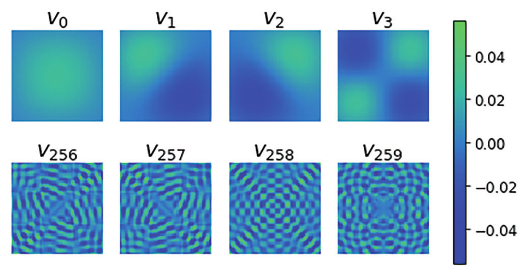
Second, the singular vectors and become more and more oscillatory as increases. Figure 9 shows images representing eight right singular vectors () of the blurring matrix constructed above and demonstrates how the frequency of the oscillations increases as increases. Since the blurring matrix spreads out any peaks in an image, it tends to dampen high-frequency oscillations. Therefore, a right singular vector representing a high frequency will correspond to a small singular value since . This oscillatory behavior of the singular vectors and their relation to the singular values appears more generally with other blurring operators defined by other kernels and in other discrete ill-posed inverse problems due to the underlying continuous model 10.
Images corresponding to eight right singular vectors .
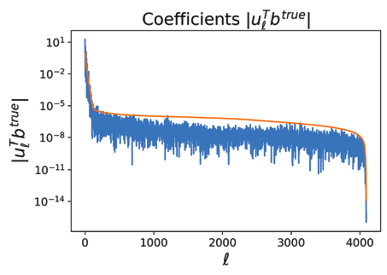
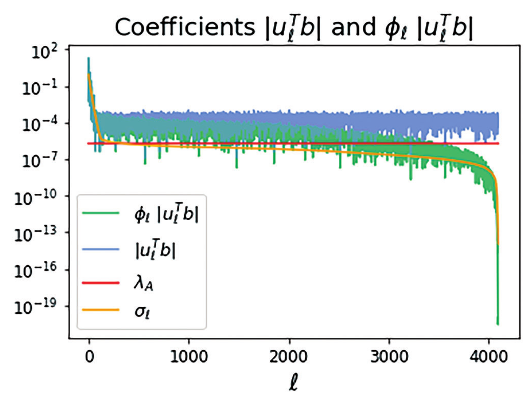
The third property of discrete linear ill-posed problems is known as the discrete Picard condition, which says that the coefficients of expressed in the left singular basis, , on average, decay to zero faster than the singular values 10. This is illustrated on the top of Figure 10, which shows both and the singular values . Since , the discrete Picard condition holds when the original image is not dominated by high-frequency contributions for large . This is a reasonable assumption with most digital photographs 12.
The coefficients are seen on the top while the coefficients are on the bottom.
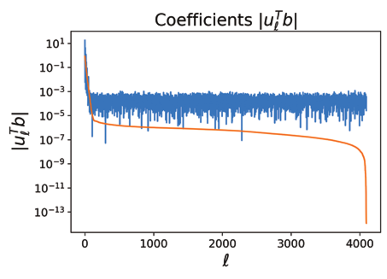
By contrast, the added white noise causes the coefficients to remain relatively constant for large , as can be seen on the bottom of Figure 10. However, both plots agree for small values of .
Writing both vectors and as a linear combination of the right singular vectors , we see that
and
Because the singular values approach zero, the coefficients grow extremely large, as seen in Figure 11. Therefore, includes a huge contribution from high-frequency right singular vectors , which means that is very oscillatory and not at all related to the original image that we seek to reconstruct.
The coefficients of and .
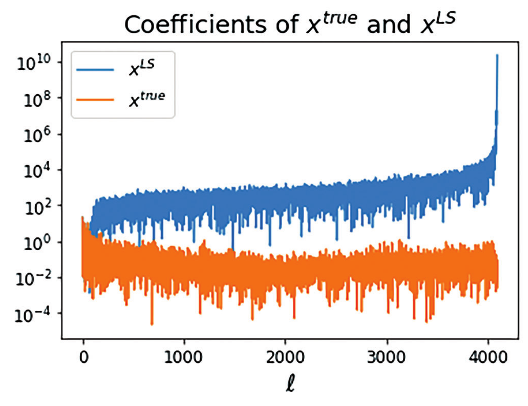
We also note here that the size of the coefficients shown in Figure 11 cause the norm to be extremely large. As we will see shortly, we will consider this norm as a measure of the amount of noise in the reconstructed image.
5. Regularization
As an alternative to accepting as our reconstructed image, we instead approximate by filtering out the contributions from the high-frequency singular vectors, which are magnified through division by small singular values, while retaining as much information as possible from the measured data . While we know the noise vector in the example presented here, in practice we do not, which means we cannot expect to get rid of the noise completely. Therefore, the goal is to design filtering methods that dampen the effects of the noise given that very little is known about it. This process is known as regularization, and there are several possible approaches we can follow.
A first natural idea is to introduce a set of filtering factors on the SVD expansion and construct a regularized solution as
with the filter factors being for large values of when the noise dominates and for small values of , which are the terms in the expansion where the components of and are closest.
One option is to define for smaller than some cutoff and otherwise. That is, we can simply truncate the expansion of in terms of right singular vectors in an attempt to minimize the contribution from the terms for large . Then, the obtained regularized solution would be
This solution is known as the truncated SVD (TSVD).
Remember, however, that the singular values in discrete ill-posed problems approach zero without having a gap that would form a natural cutoff point. Instead, Tikhonov regularization chooses the filtering factors
for some parameter whose choice will be discussed later. For now, notice that when and when . This has the effect of truncating the singular vector expansion at the point where the singular values pass through but doing so more smoothly. Thus, the Tikhonov solution can be written as
which may also be rewritten as
This demonstrates that solves the least squares problem
where returns the value of which minimizes the function .
Equation 2 is a helpful reformulation of Tikhonov regularization. First, writing as the solution of a least squares problem provides us with efficient computational alternatives to finding the SVD of 10. Moreover, the minimization problem provides insight into choosing the optimal value of the regularization parameter , as we will soon see.
By the way, this formulation of Tikhonov regularization shows its connection to ridge regression, a data science technique for tuning a linear regression model in the presence of multicollinearity to improve its predictive accuracy.
Let us investigate the meaning of 2. Notice that
which is relatively small. We therefore consider the residual as a measure of how far away we are from the original image . Remember that , the contributions to from the added noise, cause to be very large. Consequently, we think of the second term in 2 as measuring the amount of noise in .
The regularization parameter allows us to balance these two sources of error. For instance, when is small, the Tikhonov solution , which is the minimum of 2, will have a small residual at the expense of a large norm . In other words, we tolerate a noisy regularized solution in exchange for a small residual. On the other hand, if is large, the Tikhonov solution will have a relatively large residual in exchange for filtering out a lot of the noise.
6. Choosing the Regularizing Parameter
When applying Tikhonov regularization for solving discrete ill-posed inverse problems, a question of high interest is: How can we define the best regularization parameter ? A common and well known technique is to create a log-log plot of the residual norm and the solution norm as we vary . This plot, as shown in Figure 12, is usually called an -curve due to its characteristic shape 13.
As mentioned earlier, small values of lead to noisy regularized solutions while large values of produce large residuals. This means that we move across the -curve from the upper left to the lower right as we increase .
The -curve in our sample deblurring problem. The three indicated points correspond to values of , and .
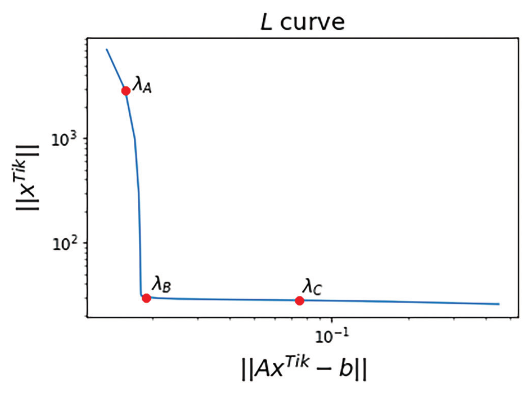
Since the filtering factors satisfy when and when , we will view the point where as an indication of where we begin filtering. Let us first consider the value , which produces the point on the -curve indicated in Figure 12. The resulting coefficients and are shown in Figure 13. Filtering begins roughly where the plot of singular values crosses the horizontal line indicating the value of .
The choice leads to under-smoothing.
While we have filtered out some of the noise, it appears that there is still a considerable amount of noise present. This is reflected by the position of the corresponding point on the -curve since the norm is relatively large. This choice of is too low, and we say that the regularized solution is under-smoothed.
Alternatively, let us consider the regularized solution constructed with as indicated on Figure 12. This leads to the coefficients and shown in Figure 14.
The choice leads to over-smoothing.

In this case, we begin filtering too soon so that, while we have filtered the noise, we have also discarded some of the information present in , which is reflected in the relatively large residual . This choice of is too large, and we say that the Tikhonov solution is over-smoothed.
Finally, considering the case where gives the Tikhonov solution that appears at the sharp bend of the -curve in Figure 12. The resulting coefficients shown in Figure 15 inspire confidence that this is a good choice for .
The choice gives the optimal amount of smoothing.

In this case, decreasing causes us to move upward on the -curve; we are allowing more high-frequency components into the solution without improving the residual. Increasing causes us to move right on the -curve; we are losing information as the residual increases without removing relevant high-frequency components. Therefore, is our optimal value.
Figure 16 shows the image obtained using this optimal parameter . While it is not a perfect reconstruction of the original image , it is a significant improvement over the recorded image . Accurately reproducing the sharp boundaries that occur in requires high-frequency contributions that we have necessarily filtered out.
The reconstructed image using the regularization parameter determined by the -curve is seen on the right, along with the original image on the left for comparison.

The -curve furnishes a practical way to identify the optimal regularizing parameter as there are techniques that allow us to identify the point of maximal curvature by computing the Tikhonov solution for just a few choices of . However, this technique should not be applied uncritically as there are cases in which the optimal Tikhonov solution does not converge to the true image as the added error approaches zero.
An alternative technique, known as the Discrepancy Principle 6, relies on an estimate of the size of the error . Remember from 3 that we have . Moreover, the SVD description of provides a straightforward explanation for why the residual is an increasing function of . If we know , we simply choose the optimal to be the one where .
Other well-known methods for choosing the parameter include the Generalized Cross Validation (GCV) 8, that chooses to maximize the accuracy with which we can predict the value of a pixel that has been omitted, the unbiased predictive risk estimator (UPRE) 15, and more recently, methods based on learning when training data are available 4. Most of these methods can also be used to find the regularization parameter involved in the TSVD solution.
7. Other Regularization Techniques
Looking at the variational formulation 2 of Tikhonov regularization, it is easy to see how it can be extended to define other regularization methods by, for example, using different regularization terms.
7.1. General-form Tikhonov regularization
The Tikhonov regularization formulation 2 can be generalized to
by incorporating a matrix , which is called the regularization matrix 10. Its choice is problem dependent and can significantly affect the quality of the reconstructed solution. Several choices of the regularization matrix involve discretization of the derivative operators or framelet and wavelet transformations depending on the application. The only requirement on is that it should satisfy
where denotes the null space of the matrix . The general Tikhonov minimization problem 4 has the unique solution
for any .
The reconstructed images using the optimal regularization parameter and the discretization of the first derivative operator with the 2-norm regularization on the left, and TV regularization on the right.


In Figure 17, we reconstruct the image by applying the discretization of the two-dimensional first derivative operator for zero boundary conditions, that is, the matrix takes the form of
where is the Kronecker product 9 defined, for matrices and , by
7.2. Total variation regularization
In many applications, the image to be reconstructed is known to be piece-wise constant with regular and sharp edges, like the one we are using as an example in this article. Total variation (TV) regularization is a popular choice that allows the solution to preserve edges 17. Such regularization can be formulated as
where is the anisotropic TV operator, which once discretized, is the same as 5. Looking at Figure 17, we can see that even though we are using the same operator , the norms used in the regularization terms are different and that makes a huge difference. But there is a higher cost to finding the TV solution due to the fact that the minimization functional is not differentiable. Still, there are many algorithms to find its minimum. Here, we apply the Iteratively Reweighted Least Squares (IRLS), which solves a sequence of general-form Tikhonov problems 16. So, instead of solving only one Tikhonov problem, we solve many.
The TV approach is also very commonly used in compressed sensing where the signal to be reconstructed is sparse in its original domain or in some transformed domain 2.
8. Matrix Structures
8.1. BTTB structure
Because these are usually large-scale problems, it is useful to consider the structure of the matrix . For instance, when considering a spatially invariant blur and assuming that the image has zero boundary conditions, the matrix exhibits a Block-Toeplitz-Toeplitz-Block (BTTB) structure 12 in which appears as a block-Toeplitz matrix with each block being a Toeplitz matrix. That is,
where for , we have
Notice that to generate these matrices, we only need the first row and column of each matrix , which form the Toeplitz vector .
8.2. BCCB structure
Another feasible structure arises when still considering a spatially invariant blur but assuming that the image has periodic boundary conditions. In this case, the matrix has a Block-Circulant-Circulant-Block (BCCB) structure, that is, a block-circulant matrix with each block being a circulant matrix,
where for ,
Typically, the matrix is not formed explicitly. Notice that to generate these matrices, we only need the first row of each matrix , , so we do not need to store every entry of the matrix , only the vectors that define the matrices . Furthermore, BCCB matrices are diagonalizable by the two-dimensional Discrete Fourier Transform (DFT) with eigenvalues given by the Fourier transform of the first column of . Therefore, the Tikhonov solution can be computed efficiently as
where is the matrix representing (i.e., ), the matrix contains the eigenvalues of , conj() denotes the component-wise complex conjugate, is the matrix whose entries are the squared magnitudes of the complex entries of , is a matrix of all ones, and and denote the Hadamard product (also known as Schur product) and Hadamard division, respectively, which are the element-to-element operations between matrices. Notice that IDFT stands for Inverse Discrete Fourier Transform. For more details, we direct the reader to 12.
8.3. Separable blur operator
Another special case is when the blurring operator is separable, which means that the blurring can be separated in the horizontal and vertical directions as illustrated in Equation 1; that is, the matrix can be written as
If we have the SVDs and , we basically have the SVD of by writing
except that the elements in the diagonal matrix might not be in the decreasing order, and therefore some reordering might be needed. So, the Tikhonov solution can be efficiently computed as
where and are column vectors containing the diagonal elements of and , respectively, and is a matrix containing the squared elements of the matrix .
Notice that if and are Toeplitz matrices, then has BTTB structure, and if and are circulant matrices, then has BCCB structure.
9. Multilevel Methods
Because dealing with images of large size is difficult, researchers keep working on finding ways to solve these large-scale inverse problems efficiently. Another possible way to solve these problems is by means of multilevel methods. The main idea of a multilevel method is to define a sequence of systems of equations decreasing in size,
where the superscript denotes the -th level ( = 0 being the original system), and to get either an approximate solution, a correction to a current solution, or some other information at each level, where the computational cost would be smaller than solving the original system. At each level, the right-hand side is defined by
and the matrix by
where is called the restriction operator, which maps a vector into a lower dimensional space by, for example, sampling or averaging, and is the interpolation operator, which maps a vector into a higher dimensional space.
There are many ways of defining and using such a sequence of systems of equations to solve many different mathematical problems. Some references related to multilevel methods for image deblurring applications include 35714.
9.1. Wavelet-based approach
Here, we consider the use of wavelet transforms as restriction and interpolation operators. In particular, we will work with the Haar Wavelet Transform (HWT) because, as we will see, it preserves the structures of the matrices involved.
The one-dimensional HWT is the orthonormal matrix defined by
where and have dimension . The two-dimensional HWT can be defined in terms of the one-dimensional HWT by with . So, we define the restriction operator by and the interpolation operator by .
To motivate the use of HWT as a restriction operator, on the left of Figure 18, we can see the coarser version of defined by . This is a image that still conveys most of the information in the original image with the letter H, which demonstrates that reconstructing a coarse version may be enough for some applications. This can allow us to compress images to save storage space or bandwidth. For instance, suppose that before transmitting the image , we compute its coarser version and transmit just (see right of Figure 18). The image might have enough information to recover .
The compressed true image on the left and blurred and noisy image on the right.


What is the right blurring matrix to recover from ? Using our example, we will show that using does a good job. Figure 19 shows the Tikhonov and TV solutions of the system . Notice that we are solving a system with a matrix instead of the original system with a matrix.
The following theorem shows that the HWT preserves the structures of the matrices described before.
Let be a matrix with Toeplitz structure and with Toeplitz vector , and . Then, the matrix is also Toeplitz with Toeplitz vector , where with being the Toeplitz matrix with Toeplitz vector with all zeros and and .
The reconstructed coarse images of size , obtained using the optimal regularization parameter and the discretization of the first derivative operator with the 2-norm regularization on the left, and TV regularization on the right.


A similar result can be shown for circulant matrices.
Let be a circulant matrix and . Then, the matrix is also circulant.
Let us consider the case when . Then, by a property of the Kronecker product, we have that
The matrix is separable. Furthermore, by Theorem 1, if and are Toeplitz matrices, then and are too. Applying this same argument repeatedly, we obtain that is separable by two Toeplitz matrices and therefore BTTB for all levels . Similarly, by Corollary 1, is separable by two circulant matrices and therefore BCCB for all levels . Therefore, the initial structure of the matrix is inherited by all the levels.
For the case when we have BCCB structures, we can solve the corresponding Tikhonov systems at all levels using Fourier-based methods. If we are dealing with separable matrices with Toeplitz structure, we could go down several levels until we can compute the SVD of and , and use that
This gives us basically the SVD of , except that the elements in the diagonal matrix might not be in the decreasing order, and therefore some reordering would be needed.
10. Conclusions and Outlook
Our intention has been to introduce readers to the problem of image deblurring, the mathematical issues that arise, and a few techniques for addressing them. As mentioned in the introduction, these techniques may be applied to a wide range of related problems. Indeed, we outlined a number of alternative strategies, for example, in choosing appropriate boundary conditions or in selecting the best regularization parameter, as some strategies are better suited to a specific range of applications.
Most of the methods that we have described are primarily based around direct factorizations. However, when dealing with unstructured and very large matrices, iterative methods may need to be used instead. There is an extensive literature on iterative methods 18, but a discussion about them is outside the scope of this introductory article.
We believe this subject is accessible to both undergraduate and graduate students and can serve as a good introduction to inverse problems, working with ill-conditioned linear operators, and large-scale computation. The visual nature of the problem provides compelling motivation for students and allows the efficacy of various techniques to be easily assessed. Some introductory books on this subject include 111220.
In addition, this field is an active area of research that is connected to recent developments in machine learning and convolutional neural networks. For example, many classical techniques that have traditionally been used in image deblurring can be used to speed up the training of machine learning models, such as neural nets designed to classify images. Earlier we mentioned that Tikhonov regularization is related to ridge regression, a fundamental tool in machine learning. Indeed, the connection to machine learning goes much deeper.
The code to generate the figures appearing in this article is available at https://github.com/ipiasu/AMS_Notices_AEP. This manuscript contains only a limited number of references because journal rules restrict the maximum number of references to 20; additional references can also be found in the github link.
References
- [1]
- Messier 100 shows improvements of Hubble, https://esahubble.org/images/potw1850b/.Show rawAMSref
\bib{Hubble}{misc}{ title={{M}essier 100 shows improvements of {H}ubble, \url {https://esahubble.org/images/potw1850b/}}, }Close amsref.✖ - [2]
- Emmanuel J. Candès, Justin K. Romberg, and Terence Tao, Stable signal recovery from incomplete and inaccurate measurements, Comm. Pure Appl. Math. 59 (2006), no. 8, 1207–1223, DOI 10.1002/cpa.20124. MR2230846Show rawAMSref
\bib{candes2006stable}{article}{ author={Cand\`es, Emmanuel J.}, author={Romberg, Justin K.}, author={Tao, Terence}, title={Stable signal recovery from incomplete and inaccurate measurements}, journal={Comm. Pure Appl. Math.}, volume={59}, date={2006}, number={8}, pages={1207--1223}, issn={0010-3640}, review={\MR {2230846}}, doi={10.1002/cpa.20124}, }Close amsref.✖ - [3]
- Raymond H. Chan and Ke Chen, A multilevel algorithm for simultaneously denoising and deblurring images, SIAM J. Sci. Comput. 32 (2010), no. 2, 1043–1063, DOI 10.1137/080741410. MR2639605Show rawAMSref
\bib{chan2010multilevel}{article}{ author={Chan, Raymond H.}, author={Chen, Ke}, title={A multilevel algorithm for simultaneously denoising and deblurring images}, journal={SIAM J. Sci. Comput.}, volume={32}, date={2010}, number={2}, pages={1043--1063}, issn={1064-8275}, review={\MR {2639605}}, doi={10.1137/080741410}, }Close amsref.✖ - [4]
- Julianne Chung and Malena I. Español, Learning regularization parameters for general-form Tikhonov, Inverse Problems 33 (2017), no. 7, 074004, 21, DOI 10.1088/1361-6420/33/7/074004. MR3672233Show rawAMSref
\bib{chung2017learning}{article}{ author={Chung, Julianne}, author={Espa\~{n}ol, Malena I.}, title={Learning regularization parameters for general-form Tikhonov}, journal={Inverse Problems}, volume={33}, date={2017}, number={7}, pages={074004, 21}, issn={0266-5611}, review={\MR {3672233}}, doi={10.1088/1361-6420/33/7/074004}, }Close amsref.✖ - [5]
- Marco Donatelli and Stefano Serra-Capizzano, On the regularizing power of multigrid-type algorithms, SIAM J. Sci. Comput. 27 (2006), no. 6, 2053–2076, DOI 10.1137/040605023. MR2211439Show rawAMSref
\bib{donatelli2006regularizing}{article}{ author={Donatelli, Marco}, author={Serra-Capizzano, Stefano}, title={On the regularizing power of multigrid-type algorithms}, journal={SIAM J. Sci. Comput.}, volume={27}, date={2006}, number={6}, pages={2053--2076}, issn={1064-8275}, review={\MR {2211439}}, doi={10.1137/040605023}, }Close amsref.✖ - [6]
- H. W. Engl, Discrepancy principles for Tikhonov regularization of ill-posed problems leading to optimal convergence rates, J. Optim. Theory Appl. 52 (1987), no. 2, 209–215, DOI 10.1007/BF00941281. MR879198Show rawAMSref
\bib{engl1987discrepancy}{article}{ author={Engl, H. W.}, title={Discrepancy principles for Tikhonov regularization of ill-posed problems leading to optimal convergence rates}, journal={J. Optim. Theory Appl.}, volume={52}, date={1987}, number={2}, pages={209--215}, issn={0022-3239}, review={\MR {879198}}, doi={10.1007/BF00941281}, }Close amsref.✖ - [7]
- Malena I. Español and Misha E. Kilmer, Multilevel approach for signal restoration problems with Toeplitz matrices, SIAM J. Sci. Comput. 32 (2010), no. 1, 299–319, DOI 10.1137/080715780. MR2599779Show rawAMSref
\bib{espanol2010multilevel}{article}{ author={Espa\~{n}ol, Malena I.}, author={Kilmer, Misha E.}, title={Multilevel approach for signal restoration problems with Toeplitz matrices}, journal={SIAM J. Sci. Comput.}, volume={32}, date={2010}, number={1}, pages={299--319}, issn={1064-8275}, review={\MR {2599779}}, doi={10.1137/080715780}, }Close amsref.✖ - [8]
- Gene H. Golub, Michael Heath, and Grace Wahba, Generalized cross-validation as a method for choosing a good ridge parameter, Technometrics 21 (1979), no. 2, 215–223, DOI 10.2307/1268518. MR533250Show rawAMSref
\bib{golub1979generalized}{article}{ author={Golub, Gene H.}, author={Heath, Michael}, author={Wahba, Grace}, title={Generalized cross-validation as a method for choosing a good ridge parameter}, journal={Technometrics}, volume={21}, date={1979}, number={2}, pages={215--223}, issn={0040-1706}, review={\MR {533250}}, doi={10.2307/1268518}, }Close amsref.✖ - [9]
- Gene H. Golub and Charles F. Van Loan, Matrix computations, 4th ed., Johns Hopkins Studies in the Mathematical Sciences, Johns Hopkins University Press, Baltimore, MD, 2013. MR3024913Show rawAMSref
\bib{GVL12}{book}{ author={Golub, Gene H.}, author={Van Loan, Charles F.}, title={Matrix computations}, series={Johns Hopkins Studies in the Mathematical Sciences}, edition={4}, publisher={Johns Hopkins University Press, Baltimore, MD}, date={2013}, pages={xiv+756}, isbn={978-1-4214-0794-4}, isbn={1-4214-0794-9}, isbn={978-1-4214-0859-0}, review={\MR {3024913}}, }Close amsref.✖ - [10]
- Per Christian Hansen, Rank-deficient and discrete ill-posed problems, SIAM Monographs on Mathematical Modeling and Computation, Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA, 1998. Numerical aspects of linear inversion, DOI 10.1137/1.9780898719697. MR1486577Show rawAMSref
\bib{hansen1998rank}{book}{ author={Hansen, Per Christian}, title={Rank-deficient and discrete ill-posed problems}, series={SIAM Monographs on Mathematical Modeling and Computation}, note={Numerical aspects of linear inversion}, publisher={Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA}, date={1998}, pages={xvi+247}, isbn={0-89871-403-6}, review={\MR {1486577}}, doi={10.1137/1.9780898719697}, }Close amsref.✖ - [11]
- Per Christian Hansen, Discrete inverse problems, Fundamentals of Algorithms, vol. 7, Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA, 2010. Insight and algorithms, DOI 10.1137/1.9780898718836. MR2584074Show rawAMSref
\bib{hansen2010discrete}{book}{ author={Hansen, Per Christian}, title={Discrete inverse problems}, series={Fundamentals of Algorithms}, volume={7}, note={Insight and algorithms}, publisher={Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA}, date={2010}, pages={xii+213}, isbn={978-0-898716-96-2}, review={\MR {2584074}}, doi={10.1137/1.9780898718836}, }Close amsref.✖ - [12]
- Per Christian Hansen, James G. Nagy, and Dianne P. O’Leary, Deblurring images, Fundamentals of Algorithms, vol. 3, Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA, 2006. Matrices, spectra, and filtering, DOI 10.1137/1.9780898718874. MR2271138Show rawAMSref
\bib{hansen2006deblurring}{book}{ author={Hansen, Per Christian}, author={Nagy, James G.}, author={O'Leary, Dianne P.}, title={Deblurring images}, series={Fundamentals of Algorithms}, volume={3}, note={Matrices, spectra, and filtering}, publisher={Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA}, date={2006}, pages={xiv+130}, isbn={978-0-898716-18-4}, isbn={0-89871-618-7}, review={\MR {2271138}}, doi={10.1137/1.9780898718874}, }Close amsref.✖ - [13]
- Per Christian Hansen and Dianne Prost O’Leary, The use of the -curve in the regularization of discrete ill-posed problems, SIAM J. Sci. Comput. 14 (1993), no. 6, 1487–1503, DOI 10.1137/0914086. MR1241596Show rawAMSref
\bib{hansen1993use}{article}{ author={Hansen, Per Christian}, author={O'Leary, Dianne Prost}, title={The use of the $L$-curve in the regularization of discrete ill-posed problems}, journal={SIAM J. Sci. Comput.}, volume={14}, date={1993}, number={6}, pages={1487--1503}, issn={1064-8275}, review={\MR {1241596}}, doi={10.1137/0914086}, }Close amsref.✖ - [14]
- Serena Morigi, Lothar Reichel, Fiorella Sgallari, and Andriy Shyshkov, Cascadic multiresolution methods for image deblurring, SIAM J. Imaging Sci. 1 (2008), no. 1, 51–74, DOI 10.1137/070694065. MR2475825Show rawAMSref
\bib{morigi2008cascadic}{article}{ author={Morigi, Serena}, author={Reichel, Lothar}, author={Sgallari, Fiorella}, author={Shyshkov, Andriy}, title={Cascadic multiresolution methods for image deblurring}, journal={SIAM J. Imaging Sci.}, volume={1}, date={2008}, number={1}, pages={51--74}, review={\MR {2475825}}, doi={10.1137/070694065}, }Close amsref.✖ - [15]
- Rosemary A. Renaut, Saeed Vatankhah, and Vahid E. Ardestani, Hybrid and iteratively reweighted regularization by unbiased predictive risk and weighted GCV for projected systems, SIAM J. Sci. Comput. 39 (2017), no. 2, B221–B243, DOI 10.1137/15M1037925. MR3621270Show rawAMSref
\bib{ReVaAr17}{article}{ author={Renaut, Rosemary A.}, author={Vatankhah, Saeed}, author={Ardestani, Vahid E.}, title={Hybrid and iteratively reweighted regularization by unbiased predictive risk and weighted GCV for projected systems}, journal={SIAM J. Sci. Comput.}, volume={39}, date={2017}, number={2}, pages={B221--B243}, issn={1064-8275}, review={\MR {3621270}}, doi={10.1137/15M1037925}, }Close amsref.✖ - [16]
- Paul Rodriguez and Brendt Wohlberg, An iteratively reweighted norm algorithm for total variation regularization, Fortieth Asilomar Conference on Signals, Systems and Computers, 2006, pp. 892–896.Show rawAMSref
\bib{rodriguez2006iteratively}{inproceedings}{ author={Rodriguez, Paul}, author={Wohlberg, Brendt}, title={An iteratively reweighted norm algorithm for total variation regularization}, organization={IEEE}, date={2006}, booktitle={Fortieth Asilomar Conference on Signals, Systems and Computers}, pages={892\ndash 896}, }Close amsref.✖ - [17]
- Leonid I. Rudin, Stanley Osher, and Emad Fatemi, Nonlinear total variation based noise removal algorithms, Phys. D 60 (1992), no. 1-4, 259–268, DOI 10.1016/0167-2789(92)90242-F. Experimental mathematics: computational issues in nonlinear science (Los Alamos, NM, 1991). MR3363401Show rawAMSref
\bib{rudin1992nonlinear}{article}{ author={Rudin, Leonid I.}, author={Osher, Stanley}, author={Fatemi, Emad}, title={Nonlinear total variation based noise removal algorithms}, note={Experimental mathematics: computational issues in nonlinear science (Los Alamos, NM, 1991)}, journal={Phys. D}, volume={60}, date={1992}, number={1-4}, pages={259--268}, issn={0167-2789}, review={\MR {3363401}}, doi={10.1016/0167-2789(92)90242-F}, }Close amsref.✖ - [18]
- Yousef Saad, Iterative methods for sparse linear systems, 2nd ed., Society for Industrial and Applied Mathematics, Philadelphia, PA, 2003, DOI 10.1137/1.9780898718003. MR1990645Show rawAMSref
\bib{saad2003iterative}{book}{ author={Saad, Yousef}, title={Iterative methods for sparse linear systems}, edition={2}, publisher={Society for Industrial and Applied Mathematics, Philadelphia, PA}, date={2003}, pages={xviii+528}, isbn={0-89871-534-2}, review={\MR {1990645}}, doi={10.1137/1.9780898718003}, }Close amsref.✖ - [19]
- Jean-Luc Starck and Fionn Murtagh, Astronomical image and data analysis (2007).Show rawAMSref
\bib{starck2007astronomical}{article}{ author={Starck, Jean-Luc}, author={Murtagh, Fionn}, title={Astronomical image and data analysis}, date={2007}, }Close amsref.✖ - [20]
- Curtis R. Vogel, Computational methods for inverse problems, Frontiers in Applied Mathematics, vol. 23, Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA, 2002. With a foreword by H. T. Banks, DOI 10.1137/1.9780898717570. MR1928831Show rawAMSref
\bib{vogel2002computational}{book}{ author={Vogel, Curtis R.}, title={Computational methods for inverse problems}, series={Frontiers in Applied Mathematics}, volume={23}, note={With a foreword by H. T. Banks}, publisher={Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA}, date={2002}, pages={xvi+183}, isbn={0-89871-507-5}, review={\MR {1928831}}, doi={10.1137/1.9780898717570}, }Close amsref.✖
David Austin is a professor of mathematics at the Grand Valley State University. His email address is austind@gvsu.edu.

Malena I. Español is an assistant professor of computational mathematics at Arizona State University. Her email address is malena.espanol@asu.edu.

Mirjeta Pasha is a National Science Foundation Mathematical Sciences Postdoctoral Research Fellow at Tufts University. Her email address is mirjeta.pasha@tufts.edu.

Article DOI: 10.1090/noti2534
Credits
The opening image is courtesy of NASA/ESA.
Figures 1–19 are courtesy of Mirjeta Pasha, Malena I. Español, and David Austin.
Photo of David Austin is courtesy of David Austin.
Photo of Malena I. Español is courtesy of Malena I. Español.
Photo of Mirjeta Pasha is courtesy of Mirjeta Pasha.