Words and More Words
Here I will take a brief look at some of the ways mathematics has looked at words in the hope of exploiting the resulting ideas....
 Joseph Malkevitch
Joseph Malkevitch
York College (CUNY)
Email Joseph Malkevitch
Introduction
"Words! Words! I'm so sick of words!," Eliza Doolittle declares in her outburst dealing with the indignities Henry Higgins has put forth in her direction in the classic musical comedy My Fair Lady. On one level one empathizes with Eliza but words are special. How do they fit into the mathematical world rather than the worlds of English and language?
Mathematics, with its great intellectual curiosity for ideas, studies words from many points of view--doing what it often does, looking for patterns. In fact, the "science" of patterns is sometimes offered as a succinct definition for the subject matter of mathematics as a whole.
Here are just a few examples of connections between words and mathematics. If a browser is "fed" a string of words, it "returns" a list of prioritized web items tailored to that string. How is this feat accomplished? It might be that someone designing software to check if a particular essay has been plagiarized might turn to mathematics for assistance. Words interest molecular biologists who see the genetics of different species "spelled" out using the letters C, A, T, G in DNA alphabet soup, where they are trying to determine the genes in contrast to other DNA, junk or otherwise. If one had insights into "words" as objects onto themselves, perhaps it might help with getting insights into these situations. Here I will take a brief look at some of the ways mathematics has looked at words in the hope of exploiting the resulting ideas.

Tiling inspired by the Thue-Morse sequence, Courtesy of
Mark Dow, U. of Oregon
Fibonacci numbers and words
When you see numbers like 14523, 32145, and 11223 there are various patterns you might notice and "facts" associated with the numbers. The first two have all distinct digits. For 11223 the digits used include no digits beyond those used in the first two. All of these numbers have 5 digits and the second one can't be prime. (Primes are those positive integers bigger than 1 whose only factors are 1 and themselves.) Implicit in this discussion is that we are looking at numbers base 10, with the digits 0, 1, ..., 9. However, there is another point of view about these "numbers." They can be viewed as strings or "words." When we in America think about words we usually think about English words like scared, sacred, and scarred. These words have different meanings in English but they all use the same letters,
When mathematicians think about words they don't think about what the words mean in a particular language like English or French, they think about issues related to patterns.
Look at this sequence of numbers:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, .... (*)
and this sequence of letters:
a, ab, aba, abaab, abaababa, abaababaabaab, (**)
Note that all the strings of the sequence (**) begin with the letter a. For the first sequence (*) we got from one term to the next in the sequence by thinking of a numerical pattern. The next number in the sequence is generated by adding the two previous terms of the sequence (list).
We started sequence (*) with n = 0 so the formula above is valid for n equal to 2 or greater, and F0 = 0 and F1 = 1. (Sometimes it is convenient to start this sequence 1, 1, 2, .... rather than as has been done here.) In addition to the recursion equation (computes later values in a sequence in terms of prior ones) given above we need "initial" values or "conditions" for this recursion equation to "act" on.
Note that because integers commute, the order in which a consecutive pair is added does not matter. We could have written the "recursion" (difference equation) below instead and we would get the same sequence of integers as we see in (*):
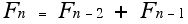
In the sequence (**), we generated a sequence of strings, and perhaps you can see the analogy between (*) and generating strings from prior strings in (**). To get the next string in (**) we take the prior string, write it down, and then follow it with the string two that preceded it. Thus, we can use the notation of recursion (difference equations) to generate a new string from a previous pair of strings by:
If we apply this recursion to the initial sequence of strings: a, ab (where n is at least 2 and treat f0= a and f1= ab) we get the sequence:
a, ab, aba, abaab, abaababa, abaababaabaab, .....
The "fancy" term for this process is concatenation: we concatenated two previous strings to get the next string. We needed initial conditions on which the recursion equation can act. It is traditional to denote concatenation using the symbol for "multiplication," as we have done above. Note that the lengths of these words are 1, 2, 3, 5, 8, 13, .... which are the numbers of the Fibonacci number sequence (starting with the third term of the way that sequence is generally described). f4 has 5 a's and 3 b's, while f5 has 8 a's and 5 b's. Can you see what the pattern is here?
We can form an infinite word (string) by thinking of the word that we are building up as the result of having each of the Fibonacci strings above as the initial part (the fancy term is prefix) of the infinite word:
f = abaababaabaab...
While, when we multiply numbers, for integers the product of x and y (xy) is the same as the product of y and x (yx), the strings xy and yx certainly look different. If one looked them up in a dictionary as if they were words, we would find xy in a different place from yx. In the mathematical study of words--strings--we treat xy and yx as different. For two strings to be the same, they must have the same length (number of symbols) in exactly the same order. So what about the recursion:
applied to the initial sequence of strings: a, b (where n is at least 2 and f0=a and f1=ab) ?
This time we get:
a, ab, aab, abaab, aababaab, abaabaababaab, ....
You can see that this sequence is different from (**) since none of the strings in (**) begin with aa, while above the strings eventually alternately begin with aa and with ab. Can you see how the sequence above is related to (**)? Below the two sequences are lined up to help you see what is going on:
a, ab, aba, abaab, abaababa, abaababaabaab, .....
a, ab, aab, abaab, aababaab, abaabaababaab, ....
Although in thinking about these strings we have used the two latin letters a and b, we could have used any two distinct symbols, including 0 and 1. An advantage of using the symbols 0 and 1 is that when we wrote down the words of (**) getting:
0, 01, 010, 01001, 01001010, 0100101001001,
it might be interesting to see what the "numerical value" in decimal these strings have.
The original sequence of numbers (*) is a very famous one in mathematics. We used the letter "F" in the notation we developed to honor the man for whom this sequence is named, Leonardo Pisano Bigolio, more commonly, Leonardo Fibonacci, or just Fibonacci.
Leonardo Fibonacci (circa 1170-1250)
Fibonacci looked at the sequence (*) in conjunction with a question about counting rabbit pairs in a special way. The Fibonacci sequence (Fibonacci numbers) is among the most studied in all of mathematics. Not only does it display wonderfully pleasing patterns but it has many applications in unexpected places, including in computer science to searching through and sorting integers.
It would be strange but creative to take the Fibonacci sequence of numbers and treat the result as, say, a number with a decimal point in front of it
.112358132134.....
We can also do something like this in binary, writing down the integers 1, 2, 3, ... represented in binary, which gives rise to what is called the Champernowne word
.110111001011101111000.....
Less strange perhaps is to form the infinite string shown below based on the entries of the Fibonacci word sequence (**) :
abaababaabaababaababaabaababaabaab.... (***)
What we have done is to create a string where each of f1, f2, f3, ... appears as an initial segment or prefix of the infinite string above. There is a sense in which this infinite string can be interpreted as a "limit" of the sequence of words in somewhat the same way that an infinite sequence of rational numbers can have a real number as its limit.
The human vision system is remarkable in being able to pick out patterns. Look at the infinite Fibonacci word above. You probably notice that there are lots of places where the pattern aa appears. However, do you see any occurrences of the pattern bb? What about the patterns aaa and bbb? Can they ever occur in the word above? The pattern aa and bb are examples of "squares" and the patterns aaa and bbb are examples of "cubes." In general a square pattern in a word is a sequence of symbols xx where x itself may be some complex string. Thus, aabaab is an example of a square.
Theorem: Any infinite word that uses only two symbols must have a square pattern.
Here is a proof using 0 and 1 as the symbols of the alphabet, since clearly it does not matter what two distinct symbols we use in our two-symbol alphabet.
Suppose the infinite word W begins with the symbol 0. If the next symbol is a zero we have the square 00, so the second symbol in W must be a 1. So far W looks like 01. Now what can be the next symbol of W? If it is a 1, we would have the square 11 in our word, so the next symbol would have to be a 0. Now, W must begin 010. And now we are stuck! If the next symbol is a 0 we have the square 00, while if the next symbol is a 1 we have (01)2 using the familiar exponential notation to mean 0101. A very similar argument can be made if our word starts with 1 instead of zero.
Note that this theorem applied not only to the particular two-symbol Fibonacci word but also to ANY infinite word constructed from 2 symbols.
So an infinite string in a two-letter alphabet must have squares. But what about cubes? A quick look at a part of the infinite Fibonacci string above may not show any cube but in fact there are cubes in this string. Can you find a copy of (baaba)3 in the string (***)? It turns out there is one!
Here is a small list of interesting "facts" about the infinite Fibonacci word:
a. The substrings 11 and 000 never appear.
While the Fibonacci sequence must contain squares, one can still investigate which squares it cannot have and which ones do appear.
b. If W is a subword of the infinite Fibonacci word, the string formed by writing the symbols of W in reverse order will also be a subword of the infinite Fibonacci word.
c. If W is a subword of the infinite Fibonacci word, W appears infinitely often.
Perhaps you find the issue of finding particular patterns of strings in a word "silly" or perhaps you find questions of this kind really intriguing. In any case, questions of this type do indeed have applications outside of mathematics. With the insight we have obtained about genetics from the Crick-Watson model for inheritance, we know that genetic information is stored in "strings" of DNA which can be coded using the 4-letter alphabet, A, T, G and C. These letters stand for the nucleotides adenine (A), thymine (T), guanine (G) and cytosine (C) (uracil, U, replaces thymine in RNA). The letter A always pairs with T in DNA, A pairs with U in RNA, and G pairs with C in both DNA and RNA.
So there may be a sequence of letters involving A, T, C, and G that has been shown to have a certain function in a mouse, and now one wants to see if there is an equivalent sequence of letters somewhere in the human genome. This leads to interest in questions about the fastest algorithm which will find a particular string in another string that involves the same alphabet. It raises interest in palindromes, strings that read the same way in both directions. Examples of such words in English are racecar and civic. The way that DNA is shuffled in the reproductive process has led to interest in DNA strings that are either palindromes or near palindromes, with a definitional twist. You will recall that DNA has the structure of a double helix consisting of two strands. The patterns of letters in one strand codes with A, T, C, G but the pattern in the other strand is always determined by the fact that A is always paired with T in the other strand, and similarly with C and G. Thus is if one has the word AATCGT on one strand, the other strand will have TTAGCA. So biologists are interested when one has a "palindromic" string, for example, AAGGTATACCTT, where its complement TTCCATATGGAA, when read in reverse order, gives the original string.
Algorithms which involve the manipulation of strings also come into play in software that is used to detect plagiarism--the using of someone else's words as if they were your own. Software can be designed to look for "exotic" phrases and then search for this exact phrase in documents that have been put onto the World Wide Web.
While many branches of mathematics have their natural roots in questions arising in science (physics, chemistry, engineering), in large countries such as Germany, France, England, Italy or Spain, the earliest work on the branch of theoretical mathematics now dubbed the combinatorics of words started in Norway and was developed in the early 20th century. Furthermore, relatively little work in this area was done until much later--the last 40 years.
Comments?
Combinatorics on words
What today is known as the combinatorics of words is tied to an important sequence in the spirit of the infinite Fibonacci word we have looked at already, which is now known as the Thue-Morse sequence or, sometimes, as the Prouhet-Thue-Morse sequence. Before saying more about this sequence itself, let me recount some of the history here.
Axel Thue was a Norwegian mathematician who lived from 1863 to 1922.
(Axel Thue (1863-1922))
He was the only doctoral student of Elling Holst who in turn was a student of the famous Norwegian mathematician M. Sophus Lie. Axel Thue had only one student, the logician Thoralf Skolem, who achieved much more fame than his thesis advisor. Thue was primarily a number theorist. His most famous work was on the approximation of real numbers using rational numbers. but he became interested in the behavior of strings, seemingly because of his interest in the theory of groups (abstract algebra). In all, Thue wrote several papers about what has come to be called the combinatorics on words. In reviewing Thue's collected works, published in 1977, Wolfgang Schmidt writes: "Thue was far ahead of his time." This is reflected in the fact that much of what he did had no immediate effect on research about combinatorics of words. Partly because his work was published in "offbeat" journals, it was not picked up immediately; it was only noticed much later how important his ideas were.
The other name associated with what is today known as the Thue-Morse sequence is that of Marston Morse. Morse was an American mathematician who lived from 1892 to 1977.

(Marston Morse (1892-1977))
Morse independently of Thue discovered the Thue-Morse sequence in the context of work in what has come to be called symbolic dynamics, which is part of the broader subject of dynamical systems that arises in topology and analysis. Loosely speakimg, the idea is to study what happens when a function is applied to an input value, and then applied again to the output, continuing in this manner and generating what are called "orbits."
Sometimes the name Eugène Prouhet (1817-1867) is also associated with the special sequence we will shortly discuss.
As of 1999 the American Mathematical Society has included this topic within its taxonomy of topics in mathematics. The combinatorics of words is listed as:
68R15 Combinatorics on words
This is the category devoted to discrete mathematics in relation to computer science. Theoretical and applied mathematicians and computer scientists alike have an interest in combinatorics on words. In the bibliography below there are several books "written" by M. Lothaire listed. However, it should be noted that M. Lothaire is not a single person, but a group of people who have pioneered in the contribution to combinatorics on words.
Comments?
Thue-Morse sequence
Before dealing with the truly extraordinary Thue-Morse sequence, let me say a bit more about how better known issues are related to some topics that come up in combinatorics of words.
Strings or words are built from symbols in an alphabet. Usually the alphabet has quite a few elements. For example with an alphabet of two symbols, say a and b, we can look at all the strings of length 4.
We can enumerate all of the strings but is there a way of counting how many strings there are? Since each position in the word being formed of length 4 can be one of two choices, we see that the first element of the string can be one of two symbols and that after this choice we can get the second element in two different ways. Using what is often referred to as the "fundamental principle of counting" we can see that there are 16 or 24 different strings.
Here is a sample:
aaaa
baaa
bbba
aabb
bbaa
bbbb
Notice that the kinds of questions we are interested in don't govern what choice of symbols we would use to represent the strings:
Thus the strings above could just as well have been written:
0000
1000
0001
0011
1100
1111
However, one advantage of using binary strings with the symbols 0 and 1 is that we can choose, if we want, to interpret the strings more easily as numbers. So in binary, 1100 represents the number twelve. Binary sequences also find applications in "codes" of different kinds. When one sees sequences involving zeros and ones, one may have a richer collection of associations than would be the case when the alphabet of two letters is a, b or +1 , -1 or X, Y.
One can use combinatorics to count how many words of length r there are using a k-letter alphabet (k at least r) that have either no repeated letters or where repeats occur.
One has to be careful what the "rules" are when discussing words. Is one interested in words only of a fixed length? Is one interested in a sequence of words? Is one interested in a string which consists of a finite number of consecutive positions in an infinite word?
To try to put your head around the distinctions here we will look at a remarkable collection of ideas that started as a contribution to theoretical mathematics over a hundred years ago. It got much less attention than it deserved because it was published in a relatively obscure journal. The notion was rediscovered later by the mathematical Marston Morse, again in a setting which was highly theoretical but quite a different setting from Axel Thue's work.
Let us try to be relatively specific but adopt a general framework for looking at "words." We will assume we are dealing with a finite alphabet of symbols. We will refer to sequences of letters drawn from the alphabet as words. Sometimes one is interested in finite length words, sometimes one-way infinite words, sometimes two way infinite words, and sometimes words whose letters are arranged in a "circuit"--cyclic words.
Here are some examples of words drawn from the three-letter alphabet a, b, c:
abcabca (finite length word)
abacabbaccabbbacccabbbaccc.... (one-way infinite word)
....abcabcabcabc...... (two-way infinite word)
Henceforth, we will only consider finite or one-way infinite words.
Now, at last, the Thue-Morse sequence. We have already noted above that any infinite word made up of zeros and ones must contain a square. A natural question is to see what kinds of patterns can be avoided in an infinite word of zeros and ones. Before you see the Thue-Morse sequence, consider the following result.
Theorem (Thue-Morse): There exists a sequence of zeros and ones with the property that it has no cubes (e.g. strings of the form xxx).
We saw previously that the Fibonacci word does have cubes, and we will see below that the Thue-Morse obeys much stronger conditions than being cube-free.
When an example or idea is "fundamental," it is common for there to be many points of view about the idea. The fact that Euler's Polyhedral Formula is fundamental is attested to by the fact that it comes up in geometry, topology, algebra, etc. and that there are many proofs of this important result. The fact that the Thue-Morse sequence is fundamental is also attested to by the wide variety of settings where it arises and the many different approaches to constructing it.
We will use TMn to denote the nth term of the Thue-Morse sequence--which I will sometimes refer to as the T-M sequence--where n takes on the values 0, 1, 2, 3, ....
To find the nth term of the T-M sequence, convert the index n to its binary representation. If this representation has an even number of 1's then TMn is 0. Otherwise it is 1. Thus, the nth entry in the sequence depends on the number of ones in the binary representation of the index n. When the number of 1's is even (e.g. 0, 2, 4, etc.), we set the term of the sequence to 0; otherwise we set the nth entry to 1.
To give you the idea, shown below are the decimal integers from 0 to 16, their binary representations, and the "parity" of the number of 1's in the binary representation of each index n. Another way of saying how one computes the entry in the third column is that it is the remainder when the number of 1's in column 2 is divided by 2. That is, each entry in the third column is the number of 1's in the corresponding entry in the second column, mod 2. This will always be either 0 or 1.
|
n in decimal |
n in binary |
Number of 1's mod 2 |
|
0 |
0 |
0 |
|
1 |
1 |
1 |
|
2 |
10 |
1 |
|
3 |
11 |
0 |
|
4 |
100 |
1 |
|
5 |
101 |
0 |
|
6 |
110 |
0 |
|
7 |
111 |
1 |
|
8 |
1000 |
1 |
|
9 |
1001 |
0 |
|
10 |
1010 |
0 |
|
11 |
1011 |
1 |
|
12 |
1100 |
0 |
|
13 |
1101 |
1 |
|
14 |
1110 |
1 |
|
15 |
1111 |
0 |
|
16 |
10000 |
1 |
Using the entries in column 3 of the table above we can write down the first 17 entries in the T-M sequence. Here they are:
0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1
If we omit the commas and extend the table, here is the (start) of the infinite word version of the T-M sequence:
T-M = 01101001100101101001011001101001....
To cement what is going on here, suppose you wanted to know what the 50th entry in T-M is. Since 50 when written in binary is 110010, which has 3 one's, we know that the TM
50 = 1.
One infinite word that rivals this one in interest is the infinite version of the Fibonacci words that we discussed earlier but using the alphabet of a and b rather than the 0 and 1 symbol alphabet. Here for comparison is an initial segment of the infinite Fibonacci word:
f = 010010100100101001010......
Here on top of one another are the Thue-Morse sequence (on top) and the Fibonacci word:
01101001100101101001011001101001
010010100100101001010......
Are there other ways of generating T-M?
Here is a recursive approach to defining the entries of the sequence!
TM
0 = 0
(a) TM
2n = TM
n and (b) TM
2n+1 is not equal to TM
n
What is going on here? When a number is doubled, what happens to its binary representation? The answer is that a zero gets added at the end which means that the number of 1's in the representation stays the same.
So TM
0 = 0 and using (b) with
n = 0 we get that TM
1 = 1. Now
n = 1, we use (a) to conclude that TM
2 is the same as TM
1 or 1, while using (b) with
n = 1 we see that TM
3 should be different from TM
1 and, thus, be 0. Continuing on in this manner we get the same values as we did previously.
If you think through the meaning of the way that the T-M is generated above, there is another nifty way of generating the T-M:
From the sequence listed from the 0th term to the 2
nth term, we will see how at each stage we can double the number entries we have in the 'infinite word." Write down those terms from the sequence and now write down this string next to the original but with the roles of 0 and 1 interchanged. Here is what you get when you carry this out:
0
01
0110
01101001
0110100110010110
01101001100101101001011001101001
which you can check is identical with what we had above but the work is much easier!
The more historical approach to generating the T-M sequence, however, involves what have come to be called a "morphism" approach. The basic idea is to start with some simple word and replace (using a function) each of the letters used in this word with some string to get a new string. Iterating this function over and over will generate longer and longer words, and the "limit" of these words is the infinite word.
In words, given a starting string S, replace 0 in the string by 01 and 1 in the string by 10. Use 0 as your starting string.
So here is what happens:
0
01
0110
01101001
01101001100101100
As you can see, this is our "old friend" the T-M sequence.
For those familiar with function notation here is how one expresses this:
tm(0) = 01; tm(1) = 10. T-M can be written tm
∞(0). This last means tm(tm(tm...(tm(0)....))). We compute the result of applying the function to get an answer starting with the string 0, and repeat applying the "substitution map" over and over again.
So, what is it that is interesting about the Thue-Morse sequence? We have already seen that with only an alphabet of two symbols we can't construct long words that don't have squares (e.g. strings like xx). This raises a variety of questions both of theoretical and applied interest:
a. What are the fewest symbols that an alphabet can have and yet admit arbitrarily large square-free words?
We will see that Axel Thue was able to construct a sequence of this kind, employing ideas related to the T-M sequence, using only an alphabet of 3 symbols--a remarkable result.
b. To what extent does the T-M sequence avoid having overlaps? An overlap in an infinite (one-way) string is a substring which looks like aZaZa where a is any single letter in the alphabet and Z is any string, possibly of length 0. When Z has length 0, then the pattern aZaZa becomes a single letter cubed (aaa). If there is no pattern of the kind aZaZa, then the (infinite) word is said to be overlap-free.
Why are overlaps of interest? Years after Thue's work biologists are trying to understand the meaning of strings of DNA in different species. Each species has a collection of genes which contain the genetic information for the species. For a long time the DNA outside the stretches which "code" information was thought to be "junk." This referred to DNA that was there but did not have any part in inheritance issues. We now know the situation is much more complex, and that DNA outside of sections that are genes may have "regulatory" or other information that governs the way(s) genes are "expressed." Very often geneticists are interested in "
tandem repeats." Locating such sections in DNA are valuable in determining a particular person's parentage and other aspects of genome determination.
Theorem: The Thue-Morse infinite word (which uses only two symbols) is overlap-free.
Here is a way to construct a word that is square free that uses only three symbols and which is based, you guessed it, on the Thue-Morse sequence.
We will use only the symbols 0, 1, 2 in the word we construct, and we will denote the sequence SF
n (for square free) where
n = 1, 2, 3, .....
SF
n will denote the number of 1's between the
nth and (
n+1)st zeros in the T-M sequence. Here is a stretch of the T-M sequence:
01101001100101101001011001101001
SF
1 is 2, since first 1 is in position 0, and the second 0 is in position 3, so there are two one's between these positions.
SF
2 is 1 since the second 0 is in position 3 and the third 0 is in position 5 so there is one one between them.
SF
3 = 0
SF
4 = 2
SF
5 = 0
SF
6 = 1
SF
7 = 2
which gives the initial section of the SF infinite word:
2102012
It is easy to see that the distance between two ones in the T-M sequence can only be 0, 1, or 2. Otherwise we would have as many as three ones in a row, the word 111, which would mean that the T-M sequence contained a cube, which (though we did not include the proof) cannot occur. Were this sequence to have a square, it can be shown that the T-M sequence would have to have an overlap, which cannot be the case. One can also find morphism approaches to constructing square free words with an alphabet of only size three.
The Thue-Morse, though seemingly having a primarily combinatorial and algebraic quality, has also inspired geometrical work and artistic work. Tilings, freezes, knots, and fractals all have been investigated inspired by the Thue-Morse sequence. A sample appears below (and at the beginning of the column), due to
Mark Dow who works at the brain development laboratory at the University of Oregon.
(Courtesy of Mark
Dow, University of Oregon)
In recent years there has been a tremendous explosion of results in the combinatorics of words, connections being found to matrix theory, automata theory, graph theory, etc. I think Eliza Doolittle would have approved no matter what Henry Higgins might have said!
Comments?
Bibliography
Allouche, J-P. and J. Shallit. The ubiquitous prouhet-thue-morse sequence, in Sequences and their applications, pp. 1-16. Springer, London, 1999.
Allouche, J-P. and J. Shallit. Sums of Digits, Overlaps, and Palindromes, Discrete Mathematics & Theoretical Computer Science 4 (2000) 1-10.
Allouche, J.-P. and J. Shallit, Automatic Sequences: Theory,
Applications, Generalizations, Cambridge, 2003.
Berstel, J., Axel Thue’s work on repetitions in words, Séries formelles et combinatoire algébrique 11 (1992) 65-80.
Berstel, J. and L. Boasson, Partial words and a theorem of Fine and Wilf, Theoret. Comput. Sci. 218 (1999)
135–141.
Berstel, J. and J. Karhumäki, Combinatorics on words: A tutorial, Bull. Eur. Assoc. Theor. Comput. Sci. EATCS 79 (2003) 178–228.
Berstel, J., Axel Thue's work on repetitions in words. In P. Leroux, C. Reutenauer (Eds.) Séries Formelles et Combinatoire Algébrique (Number 11 in Publications du LACIM, Université du Québec â Montréal, 1992 ), pp 65–80.
Berstel, J. and D. Perrin, The origins of combinatorics on words, European Journal of Combinatorics 28 (2007) 996-1022.
Chao, K-M. and L. Zhang, Sequence Comparsion, Springer, New York, 2009.
Crochemore, M., Sharp characterizations of squarefree morphisms, Theoret. Comput. Sci. 18 (1982) 221–226.
Crochemore, M. and D. Perrin, Two-way string matching, J. ACM 38, 651–675, 1991.
Crochemore, M. and W. Rytter, Jewels of Stringology, World Scientific, 2002.
Crochemore, M. and W. Rytter, Text Algorithms, Oxford University Press, 1994.
Crochmore, M. and C. Hancart, T. Lecroq, Algorithms on Strings, Cambridge U. Press, 2007.
Farach-Colton, M., (ed.), Combinatorial Pattern Matching, Lecture Notes in Computer Science, Volume 1448, Springer, New York, 1998.
Fine, N. and H. Wilf, Uniqueness theorems for periodic functions, Proc. Amer. Math. Soc. 16 1965 109–114.
Gusfield, D., Algorithms on Strings, Trees, and Sequences, Cambridge U. Press, New York, 1997.
Lothaire, M., Combinatorics on Words, Addison-Wesley, 1983.
Lothaire, M., Algebraic Combinatorics on Words, Cambridge University Press, New York, 2002.
Lothaire, M. Applied Combinatorics on Words, Cambridge U. Press, New York, 2005.
Louck, J., Problems in combinatorics on words originating from discrete systems, Ann. Comb., 1 (1997) 99–104.
Morse, M., Recurrent geodesics on a surface of negative curvature, Trans. Am. Math. Soc. 22 (1921) 84–100.
M. Morse, A solution of the problem of infinite play in chess, Bull. Am. Math. Soc., 44 (1938) 632.
M. Morse and G. Hedlund, Symbolic dynamics, Am. J. Math. 60, (1938) 815–866.
Nagell, T., and A. Selberg, S. Selberg, K. Thalberg. Selected mathematical papers of Axel Thue. Universitetsforlaget, Oslo, 1977.
Navarro, G. and M Raffinot, Flexible Pattern Matching in Strings, Cambridge U. Press, New York, 2002.
Offner, C., Repetitions of words and the Thue-Morse sequence. (Preprint)
Palacios-Huerta, I., Tournaments, fairness and the prouhet-thue-morse sequence, Economic inquiry 50 (2012) 848-849.
Séébold, P ., On some generalizations of the Thue–Morse morphism, Theoretical computer science 292, (2003) 283-298.
Shallit, J. O. and J. Shallit. A second course in formal languages and automata theory, Vol. 179. Cambridge: Cambridge University Press, New York, 2009.
Thue, A., Uber unendliche Zeichenreihen, Kra. Vidensk. Selsk. Skrifter. I. Mat.-Nat. Kl., Christiana, Nr. 7, 1906.
Thue, A., Uber die gegenseitige Lage gleicher Teile gewisser Zeichenreihen, Kra. Vidensk. Selsk. Skrifter. I. Mat.-Nat. Kl., Christiana, Nr. 12, 1912.
Williamson, Christopher, An overview of the Thue-Morse sequence. (Unpublished manuscript.)
Note: Jeffrey Shallit maintains a Wiki where those interested in the combinatorics on words can interact and post informaton about combinatorics on words problems and ideas.
Those who can access JSTOR can find some of the papers mentioned above there. For those with access, the American Mathematical Society's MathSciNet can be used to get additional bibliographic information and reviews of some these materials. Some of the items above can be found via the ACM Portal, which also provides bibliographic services.
Comments?
Joseph Malkevitch
York College (CUNY)
Email Joseph Malkevitch



