Bin Packing and Machine Scheduling
5. The list processing algorithm for machine scheduling
A very simplified approach to machine scheduling will now be given. The scheduling problems we consider are completely deterministic. This means that the times for completing every task making up a complex job are known in advance. Furthermore, we are given a directed graph which is called a task-analysis digraph, which indicates which tasks come immediately before other tasks. An arrow from task Ti to Tj means that task Ti must be completed before task Tj can begin. Such restrictions are very common in carrying out the individual tasks that make up a complex job. We all know that in building a new home, the laying of the foundation must occur before the roof is put on. Note that this digraph will have no directed circuit (e.g a way to follow edges and start at a vertex and return there) because that would lead to a contradiction in the precedence relations between the tasks. Also, in the task-analysis digraph below, each vertex, which represents a task, has the time for the task inside the circle corresponding to that vertex.
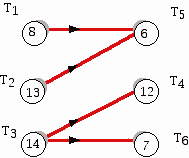
Figure 1
We want to schedule these six tasks on some fixed number of identical machines in such a manner that the tasks are completed by the earliest possible time. This is sometimes referred to as finding the makespan for the tasks that make up the job. We also want to be specific about which tasks should be scheduled on which machines during a given time period. We will assume that the scheduling is carried out so that no machine will remain voluntarily idle, and that once a machine begins working on a task it will continue to work on it without interruption until the task is completed.
There is an appealing heuristic with which to approach this problem. The heuristic has the advantage of being relatively simple to program on a computer, and when carried out by hand by different people, leads to the same schedule for the tasks (because the ways ties can be broken is specified). Typically, the heuristic gives a good approximation to an optimal schedule. This algorithm (heuristic) is known as the list processing algorithm. The algorithm works by coordinating the scheduling of the tasks on the machines and taking account of a "priority list" and then coordinating this list with the demands imposed by the task analysis digraph.
You can think of the given list as a kind of priority list which is independent of the scheduling requirements imposed by the task analysis digraph. The tasks are given in the list so that when read from left to right, tasks of higher priority are listed first. For example, the list may reflect an ordering of the tasks based on the size of cash payments that will be made when the tasks are completed. Alternatively, the list may have been chosen with the specific goal of trying to minimize the completion time for the tasks.
With respect to constructing a schedule, a task is called ready at a time t if it has not been already assigned to a processor and all the tasks which precede it in the task analysis digraph have been completed by time t. For the task analysis digraph in Figure 1 the tasks ready at time 0 are T1, T2, and T3. Remember that we are assuming that machines do not stay voluntarily idle. This means that as soon as one processor's task is completed, it will look for a new task on which to work. In determining what this next task should be, one takes into account where on the priority list the task appears, as well as any constraints imposed by the task analysis digraph. A machine will stay idle for a period of time only if there are no ready tasks (unassigned to other machines) that are ready at the given time.
The list processing heuristic assigns at a time t a ready task (reading from left to right) that has not already been assigned to the lowest-numbered processor which is not currently working on a task.
As an example, consider trying to schedule the tasks in Figure 1 on two machines. I will refer to the two machines which must be scheduled as Machines 1 and 2. Suppose we are given the list L = T1, T2, T3, T4, T5, T6. At time 0, Machine 1 being idle, and T1 being ready and first in the list, we can schedule T1 on Machine 1, which will keep that machine busy until time 8. Now Machine 2 is free at time 0 so it also seeks a task to work on at time 0. The next task in the list, T2, is ready at 0 so Machine 2 can start at time 0 on task T2. Both machines are now "happily" working until time 8 when Machine 1 becomes free. Since T3 is next in the priority list, and its predecessors (there are none) are done at time 8, Machine 1 can work on this task because it is ready at time 8. However when time 13 comes, Machine 2, just finishing T2, would like to begin the next task in the priority list which has not yet been assigned to a machine. This would be T4 but this task is not ready at time 13 because T3 has not been completed. So Machine 2 tries the next task in the priority list, T5, and this task being ready at 13 (both T1 and T2 are done) can be assigned to Machine 2. You can keep track of what is going on in Figure 2 below where the tasks assigned to Machine 1 are represented in the top row and the tasks assigned to Machine 2 are shown in the bottom row. Idle time on a machine is represented in blue.
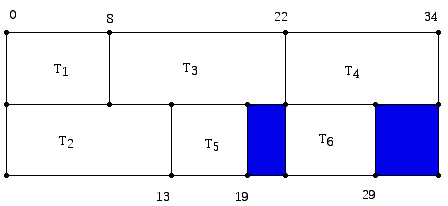
Figure 2
Continuing our analysis of how Figure 2 is generated, what happens when time 19 arrives, and Machine 2 tries to find an unassigned task in the priority list? Since both task T4 and T6 are not ready at time 19 (because they can only begin when T3 is done), Machine 2 will stay idle until time 22. At time 22, both machines are free, and in accordance with our tie-breaking rule, T4 gets assigned to Machine 1 while T6 gets assigned to Machine 2. The completion time for this list is 34.
Is this the best we can do? One way to check, when task times are integers, is that we know that a lower bound for completing the tasks is the ceiling function applied to the following quotient: the sum of all task times divided by the number of machines. In this case, we get a lower bound of 30, which means that there is perhaps some hope of finding a better schedule, one that finishes by time 30.
In addition to 30 there is potentially another independent lower bound that we can take into account. Suppose we find the length of all the paths in the task analysis digraph. In this example, two typical such paths are T2, T5 and T3, T4. The lengths of these two paths, computed by summing the numbers inside the vertices making up the paths, are respectively, 19 and 26. How are these numbers related to the completion time for all of the tasks? Clearly, since we are working with directed paths, the early tasks in the paths must be completed before the later ones. Thus, the completion time for all the tasks is at least as long as the time necessary to complete all of the tasks in any of the paths in the task analysis digraph. In particular, the earliest completion time is at least as long as the length of the longest path in this digraph. In this example, the length of this longest path is 26 and the path involved is T3, T4. The path in the task analysis digraph which has the longest length is known as a critical path. A given task analysis digraph has one or more critical paths. (This is true even if the digraph has no directed edges. In this case the length of the critical path is the amount of time it takes to complete the longest task.) Speeding up tasks that are not on the critical path does not affect this lower bound, regardless of the number of machines available. The earliest completion time must still be at least as long as the critical path, despite having a lot of processors to do the tasks not on the critical path(s).
Is it possible to improve the schedule that is displayed in Figure 2? One idea is to use a list to prevent the difficulties when lengthy tasks appear late in a list or when tasks on the critical path(s) are given "high priority." Thus, one can construct the list which orders the tasks by decreasing time (ties broken in favor of tasks with a lower number). The decreasing time list in this case would be: T3, T2, T4, T1, T6, T5. This list leads to a schedule with completion time 32. You can practice trying to use the list processing algorithm on this list with 2 processors. The result is a schedule that finishes at time 32 with only 4 time units of idle time on the second processor. Here is the way the tasks are scheduled: Machine 1: T3, T4, T5; Machine 2: T2, T1, T6, idle from 28-32. Although this schedule is better than the one in Figure 2, it may not be the optimal one, because there is still hope that a schedule which uses 30 time units on each machine with no idle time is possible.
Is there another list we could try that might achieve a better completion time? We have mentioned that tasks on the critical path are "bottlenecks" in the sense that when they are delayed, the time to complete all the tasks grows. This suggests the idea of a critical path list. Begin by putting the first task on a longest path (breaking ties with the task of lowest number) at the start of the list. Now remove this task and edges that come out of it from the task analysis digraph and repeat the process by finding a new task to add to the list that is at the start of a longest path. Doing this gives rise to the list T3, T2, T1, T4, T6, T5. This list, though different from the decreasing time list actually, gives rise to exactly the same schedule we had before that finished at time 32. There are 6! = 720 different lists that can arise with six tasks, but the schedules that these lists give rise to need not be different, as we see in this case.
We have tried three lists and they each finish later than the theoretical, but a priori possible, optimum time of 30. There is also the possibility that there is a schedule that completes at time 31, with 2 units of idle time. You can check that no sum of two sets of task times yields a value of 30. You can also check that although there are two sets of task times (e.g. 13, 12, and 6; 14, 8 7) that sum to 31 and 29, no schedule based on the assignment of the associated tasks in order to schedule two machines obeys the restrictions imposed by the task analysis digraph. Thus, with a bit of effort one sees that the optimal schedule in this case completes at time 32.
The analysis of this small example mirrors the fact that for large versions of the machine scheduling problem, there is no known polynomial time procedure that will locate what the optimal schedule might be. This point brings us full circle to why the list processing heuristic was explored as a way of trying to find good approximate schedules. More is known for the case where the tasks making up the job can be done in any order, so-called independent tasks. This is the case where the task analysis digraph has no edges. Ronald Graham has shown that for independent tasks the list algorithm finds a completion time using the decreasing time list which is never more than

where T is the optimal time to schedule the tasks and m (at least 2) is the number of machines the tasks are scheduled on. This result is a classic example of the interaction of theoretical and applied mathematics.
Bin packing, an applied problem, led to many application insights as well as tools for solving a variety of theoretical problems. Bin packing relates to some machine scheduling problems, which in turn have rich connections with both pure and applied problems. Next month, I will explore some of these connections.
-
Introduction
-
Insights into solving hard problems
-
Applications of bin packing
-
Bin packing and machine scheduling
-
The list processing algorithm for machine scheduling
-
References
