Machine Scheduling Machine Scheduling
2. Modeling scheduling
What separates mathematical analysis of problems from that of other disciplines is the precision with which the investigated situation is set up. Mathematicians are careful to make sure that the terms used in describing what is being discussed are precisely defined and to be as clear as possible about the rules which relate the interaction of the objects being investigated. In scheduling problems there are many details to be considered. Here we will refer to the "work" that must be accomplished to complete a job which requires the carrying out of a collection of tasks. We are restricting our investigation to the case where only one processor can be used to work on the tasks involved. The machine may actually be the single runway at an airport, and the tasks consist of getting different kinds of planes with different skills of their pilots into the air. Many complicated details are present even in the seemingly simple environment of scheduling a single processor:
1. Are the tasks which make up the job known in advance or must one deal with the reality that part of the job is to handle any tasks which might arise unexpectedly?
Issues and examples to consider:
When a new hospital opens its emergency room, initially there may be few "tasks" (i.e. patients) to treat, but as word spreads about the availability of emergency services, more and more "tasks" in the form of patients may present themselves. The volume of patients may grow so large that the initial plan to use only one doctor (processor) may turn out not to work. One does not want the patients to die or leave because they can not be served in a reasonable amount of time.
2. Is it known exactly how long each task will take to complete on the machine?
Comments:
It is rare, except perhaps in production line manufacturing, to know exactly how long it will take for a machine to complete a task. Even in manufacturing a machine may break down, something that we can conveniently assume away as part of the mathematical analysis! Thus, scheduling can be discussed in a deterministic framework or a stochastic (chance) framework. Here we will only explore the deterministic case.
One drastic simplification in treating the tasks to be scheduled occurs when all the tasks take the same amount of time. Sometimes scheduling problems which require exponential amounts of time to solve for the general case (varying amounts of time for each task, and more than one machine) are solvable in polynomial amounts of time when all the tasks take exactly the same time to complete.
3. Some tasks must be done before others to complete a job.
Comments:
The information about precedence relations between tasks is often given using a directed graph known as a task analysis digraph, a typical example shown below:
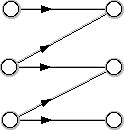
An arrow from one vertex to another indicates that the task represented by the vertex at an edge's head must be done prior to the task at the tail end of the edge. When there is no precedence requirement among the tasks, they are known as independent and can therefore be done in any order. Even for tasks which are independent, the complexity of scheduling them on a single machine (because there are other considerations involved) can be very complex.
It might seem that there is not much of interest to discuss when the tasks to be scheduled will all be done by one machine, whether or not the tasks are independent. If the tasks are independent, there are n! ways to arrangen tasks to be done by one machine and all arrangements have the same completion time. However, when there are precedences involved, not all of the n! orders are feasible, but there is at least one feasible ordering. (There may be exactly one feasible ordering, when the task analysis digraph is a path, such as that shown in the diagram below.)

Suppose we consider the situation where we must schedule n independent tasks on n machines. There are n! different schedules which arise, all of which take the same amount of time to complete, the total length of the tasks involved. How do these different schedules differ? They differ in the times that individual tasks finish. Why might it matter when individual tasks are completed? It might matter when each task has a deadline. It would matter if there are priorities, given in the form of weights for each task, which the scheduler wants to take into account. It would matter if there were penalties incurred when a task is not completed on time. If every task not only had a time length to carry out the task on the machine, but also a deadline or due date by which it had to be completed, then we could use a variety of different criteria to compare how successful different schedules were in completing each task by its deadline. Not only might a task have a deadline, but also it might have a release time: the earliest time that a task can begin. Thus, a task might not be available to start at time 0, say, but would only be available to have work begun, say, at time 7. Due dates and release times are common in scheduling problems which arise in the construction industry, though it's rare that construction industry scheduling involves a single processor! A due date is a desired time for completion of a task. Another concept is that of a deadline for a task. A deadline is an "unbreakable" due date. It is not always the case that one can schedule tasks with deadlines. In some cases there may be no way to schedule all the tasks by their deadlines.
In principle, every task might come described by three numbers: the length of time to complete the task, the earliest time, referred to a zero mark that work can be begun on that task, and a deadline time, again referred to the zero mark, when that task should ideally be completed. Clearly, it would be helpful to have a way of classifying scheduling problems because there are many different variants. Having a taxonomy of such problems not only enables one to look efficiently for whether anything is known about a particular scheduling problem, but also it allows one to summarize more easily and provide a benchmark about what is known and what is not known about scheduling problems. The notation for classifying scheduling problems works as follows, using the notation E | J | G. Loosely speaking, E denotes the environment for the scheduling situation, J stands for the job characteristics involved, and G stands for the performance measure (goal or optimization function) which is being employed. As typical examples, one might have:
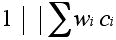
which means that on a single machine we wish to minimize the sum of the weighted completion times (ci represents the completion time of task Ti),while
means we wish to schedule two identical parallel processors, precedence relations are present (given by a task analysis digraph with arrows) and it is desired to minimize the maximum completion time of the individual tasks.
For simplicity, let us consider only the situation where tasks have time lengths and due dates, and assume that all the release times are zero.
Before looking in more detail at the amazingly complex world of scheduling even a single machine, let us look at another sense in which scheduling is complex.
- Introduction
- Modeling scheduling
- Paradoxical behavior
- Performance measures
- References
