Machine Scheduling Machine Scheduling
4. Performance measures
Do you ever "go crazy" because you have so many things to do that you do not know which to do first? In a sense scheduling life's activities is straightforward. If there are tasks we need to accomplish and we know how long each one takes, then no matter what order we do the tasks, the total time to get them done will be the same. Some of the tasks may have to be done before others but this will not affect the earliest completion time; we still have to do all the tasks in an order (though there may be many choices) consistent with the requirements as to which must be done before others. For scheduling purposes each of us is one machine. If we have only one machine and there are no precedence constraints, all the possible ways of ordering the tasks to be scheduled result in exactly the same completion time, namely the sum of the times of the tasks that make up the job. If, in solving a problem, we find more than one solution, this means that in terms of optimizing, we can add an additional criterion in deciding how to break the tie.
What objectives might we seek among all of the schedules that finish at the same time? Since we are dealing with the situation in which tasks have deadlines, we might be interested in how successful we are in meeting the desired deadlines with different schedules. To give a sense of the different cases that have been considered let us introduce some terminology. Use ci to denote the completion time that task Ti has in some schedule. Let us define the lateness of task Ti associated with a particular ordering of the tasks as being Li = ci - di where di denotes the deadline of task Ti. Note that if a task is completed before its deadline, the lateness is negative, while if a task is completed after its deadline, the lateness is positive. One can now compare different schedules by many different simple criteria based on our definitions so far. Sometimes, criteria such as those listed below are referred to as performance measures, goal functions, or objective functions. Pick the schedule based on a goal to:
a. Minimize the total (sum) of the completion times
b. Minimize the maximum lateness of the tasks
c. Minimize the total (sum) of the latenesses of all the tasks.
Note that when one minimizes the sum of either the completion times of all the tasks or the total lateness of all the tasks, one also minimizes the mean completion and the mean lateness as well. If (a) seems "artificial," imagine that when each task Ti is completed, there is a weight wi associated with this event. You can think of this weight as a kind of "priority" number associated with the completion of the task. We might now add a fourth possible goal:
d. Minimize the total sum of the weighted completion times (i.e. wici).
Condition a. now is the special case of d. where the weights assigned to all the tasks is the same.
Consider the following example consisting of three independent tasks in which the processing times for the tasks are 6, 4, and 5, respectively, and the deadline times for the same tasks are 11, 5, and 14, respectively. There are six different ways to schedule the three tasks, each of which has a finishing time of 15, the sum of the times that it takes to do the tasks.
1. T1, T2, T3
2. T1, T3, T2
3. T2, T1, T3
4. T2, T3, T1
5. T3, T1, T2
6. T3, T2, T1
The schedule that corresponds to list 1 is shown below, and reflects the task processing times of 6, 4, and 5, respectively:
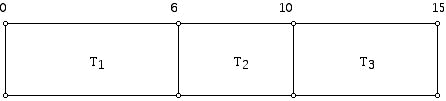
Now, for each of the schedules 1- 6 we can compute two 3-tuples indicating the completion times and lateness for each of the tasks in the schedule. The 3-tuple of completion times is shown to the left, and the 3-tuple of lateness to the right. Be careful. For example, the first 3-tuple in row 4 indicates that T1 finished at time 15, T2 at time 4, and T3 at time 9 for the 4th schedule (T2, T3, T1).
1. (6, 10, 15) (-5, 5, 1)
2. (6, 15, 11) (-5, 10, -3)
3. (10, 4, 15) (-1, -1, 1)
4. (15, 4, 9) (4, -1, -5)
5. (11, 15, 5) (0, 10, -9)
6. (15, 9, 5) (4, 4, -9)
If we sum the entries in the first 3-tuple of each line, we get 31, 32, 29, 28, 31, and 29, respectively. If we sum the entries in the second 3-tuple of each line we get 1, 2, -1, -2, 1, and -1, respectively. Finally, if we compute the maximum value for each entry in the second 3-tuple we get 5, 10, 1, 4, 10, and 4, respectively.
Given the calculations above, using criterion (a) the best schedule would be T2, T3, T1; using criterion (b) we get T2, T1, T3 as the best schedule; using criterion (c) we get T2, T3, T1 as the best schedule. Is it an accident that T2, T3, T1 is the ordering of the tasks which arises by listing the tasks in the order of their increasing processing time? In the "literature" of scheduling machines, this schedule is often known as the SPT (shortest processing time) ordering. Is it also an accident that T2, T1, T3 is the ordering of the tasks which arises by listing the tasks in the order of their increasing due dates (known as the EDD, earliest due-date ordering)? Is it an accident that the answers to (a) and (c) give rise to the same ordering of the tasks?
If all three of the solutions were different, then we would know that we are dealing with independent "objective" or goal functions. The schedule used to answer the question depends on which of the three goals one has. However, we have found that two of the answers are the same. This could be true for this particular example, but had we tried a different example, we would have seen that the two goals could lead to different answers. The other possibility is that the answer we get to what appears to be two different questions is always the same. This would mean that there would be a mathematical theorem which has the form:
If we schedule n independent tasks on one machine, the schedule that optimizes the sum of the completion times is the same schedule that optimizes the sum of the latenesses.
Indeed, the statement above is a mathematical theorem.
In addition to studying the relationships between different performance measures, mathematicians and computer scientists are also interested in finding algorithms which produce the best schedule with respect to a particular performance measure. In the example above we used "brute force" to find the optimal answers for the data given with respect to performance measures (a) - (c). This is not practical for problems where the number of tasks is large.
Happily, there are some nice general results that apply to the performance measures we have mentioned.
In the definition of lateness it may seem strange that one allows tasks to have negative lateness. Although one can see why a schedule might be given "extra credit" if tasks are completed before their due dates, it may also be true that having a few tasks completed early may distort the picture of how good the schedule is because a few tasks finishing very early may hide the fact that many tasks finish late. To overcome this problem researchers in scheduling machines hit upon the idea of a task's being tardy. The tardiness of task Ti in a schedule is defined to be: max {0, Li}, where, again, Li is the difference between a task's completion time and its deadline or due date. Thus, in those cases where a schedule completes a task early, the tardiness of such a task becomes 0, while, when a task is completed after its due date, its tardiness is positive. We now can define some additional measures of performance to the four previously defined. Pick the schedule based on a measure to:
(e) Minimize the maximum of the tardiness of the tasks
(f) Minimize the sum of the tardiness of the tasks
(g) Minimize the number of tasks which are tardy.
The performance measures (e) and (f) are the analogs of (b) and (c) for lateness, while (g) has quite a different flavor but seems very natural. One wants to make sure that as few jobs as possible are finished after their due dates. The theory of complexity developed by mathematicians and computer scientists provides a fascinating picture of the way that seemingly small changes in a problem affect the computational difficulty of the problem. Thus, for a single processor with independent tasks, determining the schedule which is best for performance measure (e) can be solved "quickly" using an algorithm based on EDD ideas for ordering the tasks. It has been shown that determining the solution for (f) is unlikely to be solvable in polynomial time (i.e. the problem is NP-hard). Individuals who have made significant contributions to scheduling problems involving one machine include: K. R. Baker, T. J. Hodgson, J. R. Jackson, E. L. Lawler, and J. M. Moore.
Compared with all of mathematics, machine scheduling problems definitely seem like a very limited domain. Yet, tools from many other branches of mathematics -- algebra, geometry, and analysis -- have proved to be useful here. Despite this, even problems for scheduling a single machine turn out to be incredibly hard to solve. Researchers continue to explore this amazing field not only because of the myriad applications that can be put to efficient scheduling algorithms, but also because the ideas and tools emerging in this area have cross-fertilized other areas of mathematics.
- Introduction
- Modeling scheduling
- Paradoxical behavior
- Performance measures
- References
